最近负责日志系统和数据平台的建设,需要选型一种序列化方法。国内大公司都用pb,也有一套完整的支持工具,但经过省略若干字的讨论,我们选用了avro。主要是考虑到Apache的支持,avro和Hadoop生态系统结合得很好,而使用pb的话会增加不少开发成本。此外,avro序列化性能也不错,基本和pb在一个水平。
Protobuf vs Avro
关于PB和Avro序列化的详细对比可以参考下文链接,这里给出两个示例。关键留意一下Schema Evolution时,不同序列化方法是如何处理的。
Protobuf
PB使用IDL schema定义:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}
PB序列化后的二进制格式如下:
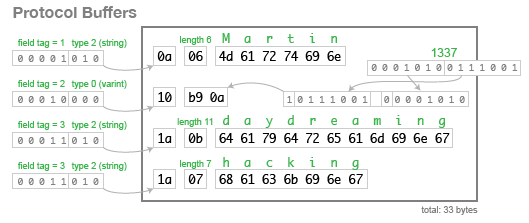
PB每个field都有唯一的tag作为标识符,可以看到序列化后的文件里,实际记录的也是该tag和对应的值。因此,每个field name其实可以变化,不会影响到序列化内容。
所以,碰到Schema Evolution时,只要保持tag不变不被替代,那么就能保持schema的前后兼容。
Avro
Avro使用JSON schema定义:
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
也可以使用IDL schema定义:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Avro序列化后的二进制格式如下:
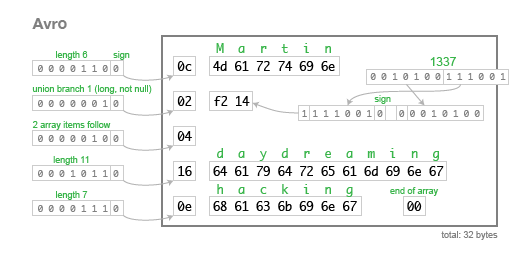
可以看出Avro序列化并没有field tag,也没有field type,所有序列化完的field基本只有长度和值,依次堆积在一起。
由于Avro并不像PB那样可以有tag标识字段,所以,Avro序列化的二进制格式和schema必须是完全对应的。如果单独拿出一个序列化完的二进制record,哪怕把原先序列化该record的schema里两个field交换了位置,也会导致反序列化失败。
Schema Evolution
可以看出Avro的实现方式虽然灵活,但一个潜在问题是序列化的内容自描述性不够强,缺少了field tag,这导致序列化结果和schema的耦合程度比我们想象的要强很多。
Avro使用的理想场景批量的序列化文件。比如,用作HDFS存储的文件格式。每个文件开头是schema描述,后面是此schema序列化记录,这样可以保证文件级别的自解析能力。如果schema有变更,则必须要新建文件。
如果想像PB那样单独处理一条record(比如RPC中),则会稍微麻烦一些。在处理单条记录的时候得额外关注该record和schema的对应关系。记住每个序列化record的反序列化都依赖生成它的schema。
在Avro中序列化和反序列化分别由writer和reader完成,它们各自和一套schema相绑定。如果writer和reader的schema不同,即存在Schema Evolution,是由Avro Parser根据一套预先定义好的resolution rules在writer和reader的schema层面解决的,如果解决不了就报错了,即双方schema不兼容。
为了保证schema前后兼容,在定义或变更avro schema时,需要注意以下几点:
- 给所有field定义default值。如果某field没有default值,以后将不能删除该field;
- 如果要新增field,必须定义default值;
- 不能修改field type;
- 不能修改field name,不过可以通过增加alias解决。
一些细节是:
- 对于union类型,default值的类型只能是union的第一个类型;
- 对于
null类型,在定义的时候需要用引号,但使用的时候不行 -_-!
比如:
{"name": "favouriteNumber", "type": ["null", "long"], "default": null}
Avro使用场景
Avro最大的优点就是和Hadoop生态衔接紧密了。比如,Hive表定义可以直接用avro schema来声明。目前有两个使用场景非常方便,一个是sqoop,一个是日志定义。
Sqoop1
用sqoop1导入MySQL数据表到Hive,想必大家也碰到过schema evolution的问题。比如,每天一个快照到Hive,如果MySQL表的定义变了,在中间新增了一列,或者改名了,那么之前的MySQL表就无法正确访问了。这一种方法是利用sqoop的--query参数,只select特定的列出来,但如果需要选择的MySQL表的列很多,那维护成本很高。
如果用avro来定义导入的Hive表的话,那么会轻松不少。
首先,用sqoop使用avro格式导入表:
sqoop-import --as-avrodatafile --table <mysql_table> --target-dir <hdfs_path> --connect jdbc:mysql://<mysql_host>/<mysql_db>?tinyInt1isBit=false --username <mysql_user> --password <mysql_password>
此时,会产生导入表的avro schema文件,比如 sqoop_import_<mysql_table>.avsc,可以用Web服务把该文件共享出去,用作创建Hive表:
CREATE EXTERNAL TABLE <hive_table>
PARTITIONED BY (ds STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION '<hdfs_path>'
TBLPROPERTIES ('avro.schema.url'='http://<some_host>/sqoop_import_<mysql_table>.avsc');
然后,把每日新增快照文件作为新的分区加入即可:
ALTER TABLE <hive_table> ADD IF NOT EXISTS PARTITION(ds='<day>') LOCATION '<hdfs_path>/ds=<day>'
如果MySQL表定义有改变,则按照Schema Evolution的规则修改sqoop_import_<mysql_table>.avsc。比如,有新增字段,那么给新增字段添加上默认值,那么Avro Parser就能按照规则解析老的avro序列化文件了。
日志定义
在使用日志训练模型的时候,经常会拍脑袋想到要增加一些特征……这就涉及到一些字段的添加。如果不用avro schema存成文本日志,那么所有添加字段只能在已有列的最末尾去顺序添加,才能保证Hive里查询的时候不至于出错。但使用avro schema之后,一方面这是个可读的schema便于沟通,另一方面按照schema evolution的规则去添加字段,可以保证整个Hive日志表都是规范的。
不过这里有个细节值得注意,就是如果一部分日志用了Avro序列化,而另外一部分是其他格式,那么在写Hadoop streaming的时候可能会有点小麻烦。如果全是avro格式,那么直接可以指定-inputformat org.apache.avro.mapred.AvroAsTextInputFormat去反序列化avro文件,转换成一行行的JSON字符串输入。
jars=/usr/lib/avro/avro.jar,/usr/lib/avro/avro-mapred.jar
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
-files $jars \
-libjars $jars \
-D mapred.reduce.tasks=5 \
-D mapred.output.compress=true \
-D mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec \
-input $input \
-output $output \
-mapper mapper.py \
-reducer reducer.py \
-file ./mapper.py \
-file ./reducer.py \
-inputformat org.apache.avro.mapred.AvroAsTextInputFormat \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner \
-jobconf mapred.job.name="jqian:$output" \
-jobconf map.output.key.field.separator=':' \
-jobconf num.key.fields.for.partition=1
但是,如果要JOIN多种格式的日志,那就有些麻烦了。此时建议就不要用Hadoop streaming了,直接用Java写MR吧。或者,用Hive streaming,依赖Hive的元数据定义的SerDe来解决这个问题。或者,用Java封装一个定制化的InputFormat,如果打死也要Hadoop streaming的话。
Avro各语言支持
虽然说avro支持很多语言,但各语言之间用起来差异不小,支持力度上 Java » Python > PHP。只有Java支持从schema生成Java代码,而Python和PHP只能先解析schema,再去做序列化。
PHP
如果是在PHP中使用avro序列化,建议先用APC保存writer,否则每个请求都要解析schema对性能影响还是不小的,具体可参考这里的测试程序。
Python
Python里用avro序列化比较自由,可以直接序列化JSON字符串。例如:
def test_serialize(schema_file, json_string):
'''read json string, return one serialized avro record'''
schema = avro.schema.parse(open(schema_file).read())
writer = StringIO()
encoder = avro.io.BinaryEncoder(writer)
datum_writer = avro.io.DatumWriter(schema)
datum = json.loads(json_string)
datum_writer.write(datum, encoder)
return writer.getvalue()
直接使用 avro.io.DatumReader 和 avro.io.DatumWriter 还是得小心,因为这种做法分离了序列化的record和schema。更常用的方法还是文件级的 avro.datafile.DataFileReader 和 avro.datafile.DataFileWriter,这样可以保证schema和序列化结果保存在一起。
Java
虽然Java提供的avro-tools.jar里有序列化JSON串的功能,但开发中还是建议不要尝试直接从JSON字符串去序列化avro。因为这会比想象得复杂,而且容易出错。
比如你有如下schema定义:
{
"type": "record",
"name": "php_svr_log",
"fields": [
{ "name": "log_id", "type": "string" },
{ "name": "log_ver", "default": "", "type": "string" },
{ "name": "device_info", "type": ["null", "string"] }
]
}
这个定义里device_info字段是optional,那么是不是可以序列化如下JSON串呢?
{"log_id": "123", "log_ver": "1.1.1"}
事实上,这个JSON字符串的确可以用上面Python的方法去序列化,但在Java里是不行的。在Java里类似下面的JSON串才能正常序列化:
{"log_id": "123", "log_ver": "1.1.1", "device_info": {"string": "ios8"} }
即所有的字段(包括optional字段)全都要在JSON里设置,并且如果是union类型字段,还需要进一步指明union的类型。为啥如此反人类,这里有一些讨论。
此外,值得一提的是,上面JSON串虽然在Java里序列化了,但Python里却又不能序列化了,因为Python不认识把union写成 {"string": "ios8"}。同样的功能两个库实现有差异,这的确容易让人迷糊。
如果直接从schema生成Java文件后再编译调用,这种方法和PB类似,就不赘述了。
如果想用动态的使用schema文件,而不是生成的Java文件,可以借助 GenericRecord 和 GenericRecordBuilder类。例如:
Schema schema = new Schema.Parser().parse(new File(schemaFile));
GenericRecordBuilder builder = new GenericRecordBuilder(schema);
builder.set("log_id", "xxx");
如果record里有的字段类型是map或者array这些类型怎么办呢?这些类型和Java数据类型是对应的,直接使用即可。例如,插入cookies信息:
Map<String, String> map = new LinkedHashMap<String, String>();
Iterator<Map.Entry<String, JsonNode>> itr = jsonRoot.get("cookies").getFields();
while (itr.hasNext()) {
Map.Entry<String, JsonNode> pair = itr.next();
map.put(pair.getKey(), pair.getValue().asText());
}
builder.set("cookies", map);
如果record里由嵌套了新的record定义怎么办呢?可以从schema里获取嵌套的record定义,然后依次赋值即可:
List<Schema> schemas = schema.getField("campaign").schema().getTypes();
GenericRecord campaign = new GenericData.Record(schemas.get(1));
// fill campaign record
builder.set("campaign", campaign);
其他工具
Avro提供了avro-tools.jar包可以对avro序列化文件做很多便捷操作,比如:
从序列化的avro文件头提取schema定义:
java -jar avro-tools.jar getschema test.avro
从序列化的avro文件打印相应的JSON:
jar -jar avro-tools.jar tojson test.avro
从JSON文件按照schema序列化到avro文件:
java -jar avro-tools.jar fromjson --schema-file test.avsc test.json