[TOC]
- 视频:http://www.chuanke.com/v2889565-173289-848527.html
- 笔记:http://www.yittoo.com/blog/index.php/2016/05/13/large-scale-ml-ctr-prediction/
- 笔记:http://www.doesbetter.com/638/
广告系统流程
- 广告位展现
- 广告候选:初选,简单规则,触发
- 点击率预估:对初选集合进行预估,机器学习方法
- 竞价排序:auction机制
维度约简
- 离散到离散 hashing:10000x1000dim (q,u)vector -> 1000dim hash table (有collision)
- 离散到统计 statistics:10000x1000dim (q,u)vector -> historic ctr, historic impr
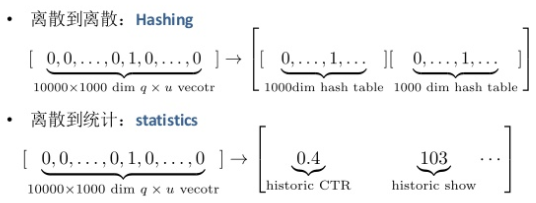
关键是减少信息的损失
分布式计算架构
- 数据并行:每台机器存储部分数据、所有参数,适合图像数据
- 模型并行:每台机器存储所有数据、部分参数,适合基因数据
- 数据模型并行:每台机器存储部分数据、部分参数,适合广告数据
技术实战
数据采样
Google KDD’13
采样
- 正样本:被点击的query
- 负样本:$r \in (0,1]$ 的概率选取未被点击的query
矫正
- $w_t = 1$ 如果事件t在被点击的query
- $w_t = \frac1r$ 如果事件t在未被点击的query
原理:采样后的期望损失等于原损失
\[E[\ell_t(w_t)]=s_tw_t\ell_t(w_t)+(1-s_t)0=s_t\frac1s_t\ell_t(w_t)=\ell_t(w_t)\]百度的改进:在期望之外还保证方差相等。
噪音检测
SA算法
计算CTR随时间变化趋势,可以把非人为的随机点击样本过滤掉。
通过对每个时间片断波峰和波谷的观察,知道随机噪音的值在什么范围,通过分值可以对噪音进行过滤。
- 随机噪音:sa=0.00275
- 正常样本:sa=-10.977
特征删减
背景:模型大小占特征大小比例极低
挑战:训练之前,判断哪些特征权值为0
特征类型:categorical features,连续值特征
特征表示:one-hot编码
Google:新特征按概率p加入;Bloom Filter+次数超过N;AucLoss升高。
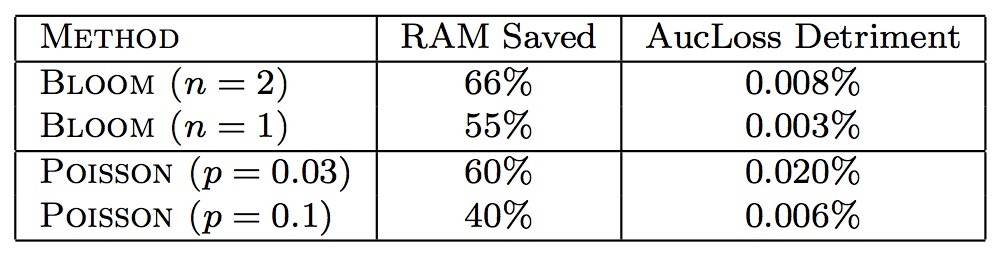
Fea-G算法
理论保证删减特征AUC效果无损
在模型训练之前,就知道几个有效特征在哪儿,或者可以找到尽可能小的包含有效特征的集合。谷歌的技术是启发性的,有可能会带来损失。而百度的技术是用理论保障,经过严格的推导,它可以在效果无损的情况下,删减的非常多的无效特征。
自动调参
AdaLasso算法
智能选择超参 $c_j$
深度特征学习技术
由于广告特征维度太高,无法直接使用DNN,解决方法:
- 特征压缩,减少特征维度
- 原始特征,找出稠密特征,在此基础上再做特征组合 【注】样本比较密集才能把一个特征描述清楚。
DANOVA
大规模稀疏特征的深度特征学习算法。听起来是分布式的ANOVA?
上线效果:特征挖掘效率显著提升上千倍;CTR、CPM显著增长
单特征->二阶组合->…->高阶组合:逐层贪婪学习
模型时效性
模型更新越快,对新广告和新广告主效果好。
要模型更新快,模型更新时,训练数据需要尽可能少。
技术挑战:稀疏性、时效性、稳定性
方法:稀疏在线算法 => 增量数据->增量模型->…->增量数据->增量模型
现状:大部分在线算法非稀疏;Google FTRL保留前N次模型梯度方法(FTRL-Proximal)——不够稳
SOA算法
模型稳定性更好
训练架构:batch处理改为online learning,节省存储资源50%以上
在线学习平台:大数据分钟级别在线学习
经验:时效性上的收益是非线性的,半小时内的收益非常显著。
模型训练
LBFGS近似Hessian矩阵,convergence较慢
寻找更好的优化方向+步长,减少迭代次数
Shooting算法
针对广告数据特征分布不均衡的特点,改进了算法迭代求解的方向和步长,在广告数据上取得了比业界常用的大规模优化算法LBFGS快十倍的性能。估计类似adagrad、adam之类?
性能变化:相比LBFGS训练轮数从平均50轮下降到5轮,且训练更充分
总结展望
- 一代:人工规则
- 二代:特征压缩,小规模非线性模型
- 三代:原始高维特征,大规模线性模型,模型实时更新
- 四代:Pulsar 大规模、复杂模型、实时更新
百度Pulsar
- 数据量:千亿样本、千亿特征
- 模型:浅层到深层灵活支持(深层代价高,对简单业务用浅层就够了)
- DNN:万亿链接神经网络
- 调研:自动化特征学习&参数调节(自适应样本采集、特征学习、参数调整、结构学习)
- 时效性:分钟级别更新模型
- 评估:可视化模型&数据分析
Reference
- FTRL-Proximal:Ad Click Prediction: a View from the Trenches, KDD’13 https://www.eecs.tufts.edu/~dsculley/papers/ad-click-prediction.pdf
- Follow-the-Regularized-Leader and Mirror Descent: Equivalence Theorems and L1 Regularization http://www.jmlr.org/proceedings/papers/v15/mcmahan11b/mcmahan11b.pdf
- 百度BDL:http://bdl.baidu.com/index.html
- BDL publications:http://bdl.baidu.com/publication.html
- A Survey of Algorithms and Analysis for Adaptive Online Learning, arxiv 2015, http://arxiv.org/pdf/1403.3465v3.pdf
- Scaling Distributed Machine Learning with the Parameter Server, OSDI’14 https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf
- A Comparison of Lasso-type Algorithms on Distributed Parallel Machine Learning Platforms, NIPS’14 http://stanford.edu/~rezab/nips2014workshop/submits/plasso.pdf
- A General Distributed Dual Coordinate Optimization Framework for Regularized Loss Minimization, arxiv 2016, http://arxiv.org/pdf/1604.03763.pdf
- Paddle:Parallel Distributed Deep Learning at Baidu https://github.com/baidu/Paddle