最近碰到一个项目需要多进程读写一份共享数据,并且共享数据的几个字段需要有倒排索引方便查询,想利用现有数据库快速建立一个原型,于是调研了一下流行的一些nosql数据库。发觉Berkeley DB虽然是一个既古老又流行的开源数据库,但是关于BDB使用的文章却很少,甚至公司DBA对BDB的特性都不太了解……于是花了好几天读了一遍BDB的references和c api,发觉BDB还是个相当复杂的系统。以下对一些常见问题做一个笔记:
数据存储
Berkeley DB的数据存储可以抽象为一张表,其中第一列是key,剩余的n-1列(fields)是value。
BDB访问数据库的方式,或者套用MySQL数据库的说法是存储引擎,有四种:
- Btree 数据保存在平衡树里,key和value都可以是任意类型,并且可以有duplicated keys
- Hash 数据保存在散列表里,key和value都可以是任意类型,并且可以有duplicated keys
- Queue 数据以固定长度的record保存在队列里,key是一个逻辑序号。这种访问方式可以快速在队列尾插入数据,然后从队列头读取数据。它的优点在于可以提供record级别的锁机制,当需要并发访问队列的时候,可以提供很好性能。
- Recno 这种访问方式类似于Queue,但它可以提供变长的record。
BDB的数据容量是256TB,单个的key或value可以保存4GB数据。
BDB是为并发访问设计的,thread-safe,且良好的支持多进程访问。
少量或者中量数据都建议使用BTREE,尤其并发的场景下,BTREE支持 lock coupling 技术,可以提升并发性能。
BDB组成
Berkeley DB内含多个独立的子系统:
- Locking subsystem
- Logging subsystem
- Memory Pool subsystem
- Transaction subsystem
一般使用的时候,这些子系统都被整合在DB environment里,但它们也单独拿出来,配合BDB之外的数据结构使用。
所谓DB Environment就是一个目录,其中保存着Locking、Logging、Memory Pool等子系统的信息,不同的thread可以打开同一个目录读写DB environment,BDB通过这种方式实现多进程/线程共享数据库。
【注意】多进程共享一个环境时,必须要使用 DB_SYSTEM_MEM,否则无法正常初始化环境。
关于DB environment的设置很多,一般没必要全部在代码里设置,也可以使用名为 DB_CONFIG 的配置文件来设置,该文件默认位于环境目录。
Concurrent Data Store (CDS)
CDS适用于多读单写的应用场景,当使用CDS的时候,仅需要 DB_INIT_MPOOL | DB_INIT_CDB 这两个子系统,不应该启用任何其他子系统,比如 DB_INIT_LOCK、DB_INIT_TXN、DB_RECOVER 等。
由于CDS并不启动lock子系统,所以使用CDS无需检查deadlock,但下面的几种情况会导致线程永远阻塞:
- 混用DB handle和cursor(此时同一thread会有两个locker竞争)。
- 当打开一个write cursor的时候,在同一个线程里有其他的cursor开启。
- 不检查BDB的错误码(当一个cursor错误返回时,必须关闭这个cursor)。
其实CDS和DS的唯一区别就在于,当要写db的时候,应该使用DB_WRITECURSOR创建一个write cursor。当这样的write cursor 存在的时候,其他试图创建 write cursor 的线程将被阻塞,直到该 write cursor被关闭。当write cursor存在的时候,read cursor不会被阻塞;但是,所有实际的写操作,包括直接调用DB->put()或者DB->del()都将被阻塞,直到所有的read cursor关闭,才会真正的写入db。这就是multiple-reader/single-writer的具体工作机制。
CDS中的注意事项
如果使用secondary database,意味着会在同一个cursor下操作两个db,此时如果用CDS,也许必须设置DB_CDB_ALLDB,但这会严重影响性能。
所谓 DB_CDB_ALLDB 是一个非常粗粒度的锁,CDS的锁基于API-layer,默认per-database,但如果设置了DB_CDB_ALL,则是per-environment,这意味着:
- 整个DB environment下只能有一个write cursor。
- 当写db的时候,整个DB environment下任何read cursor不可以打开。
读写CDS简单的做法是能用DB handle的地方直接使用DB handle,没有必要使用CURSOR handle,因为你用DB->put()或者DB->del()来修改数据库时,它内部也是调用了CURSOR handle。当然,如果你要使用CURSOR遍历数据库时,用于写的CURSOR必须设置DB_WRITECURSOR来创建:
DB->cursor(db, NULL, &dbc, DB_WRITECURSOR);
直接调用DB->put()或者DB->del(),或者先使用DB_WRITECURSOR创建CURSOR handle,最终都进入__db_cursor()函数,设置db_lockmode_t mode = DB_LOCK_IWRITE,然后用该mode加锁。但需要注意的是,不能在同一thread下混用DB和CURSOR handle,因为每个CURSOR会分配一个LOCKER,而DB handle也会分配一个LOCKER,两者可能导致self-deadlock。
如果在read lock或者write lock过程中,程序崩溃,这可能导致lock遗留在env中无法释放(可以用db_stat -CA观察到),这种情况下该environment已经损坏,只能删除该environment(删除掉__db.001之类的文件即可),重新创建。
Transactional Data Store (TDS)
TDS是使用BDB的终极方式,它适用于多读多写,并且支持Recoveriablity等任何你能想到的常见数据库特性,或者不如说,只有当你确定需要这些特性的时候,你才应该使用BDB;如果你仅仅想要一个单纯的KV系统,那也许BDB并不适合你。
一般来说,创建TDS Environment的flag如下:
DB_CREATE | DB_INIT_MPOOL | DB_INIT_LOCK | DB_INIT_LOG | DB_INIT_TXN
TDS的任何DB相关的操作都必须是事务性的,包括打开db时,都需要先创建txn:
DB_TXN* txn;
int ret = env->txn_begin(env, NULL, &txn, 0);
ret = db->open(db, txn, "test.db", NULL, DB_BTREE, DB_CREATE, 0);
// 如果使用secondary database, 则associate()调用也需要包含在txn里
ret = db->get(db, txn, &key, &val, 0);
ret = db->put(db, txn, &key, &val, 0);
if(ret) txn->abort(txn);
else txn->commit(txn, 0);
如果仅仅有读操作,其实可以无需调用commit,直接abort即可。
如果使用 DB_AUTO_COMMIT 打开db,则关于db handle的操作,不需要额外指定txn参数,此时使用了BDB的autocommit特性。
Write Ahead Logging
WAL是很多事务性数据库使用的技术,即在数据实际写入到数据库文件之前,先记录log,一旦log被写入到log文件,即认为该事务完成(并不会等待数据实际写入到数据库文件)。
这是因为log的写入始终是顺序写到文件末尾的,这比实际数据写入数据库文件(随机写入文件)要快2个数量级。
清理无用log的办法:
- 使用命令
db_archive -d - 调用
ENV->set_flags设置DB_LOG_AUTOREMOVE
Deadlock
使用TDS时,死锁原则上无法避免:
- 两个进程互相等待一块被对方锁住的资源则会发生死锁
- 甚至单一进程内试图获取一个已经被不同locker获取过的lock,也会发生死锁
采用BTREE/HASH访问方式下,并发操作时,无法避免死锁,因为page splits随时可能发生,见图:
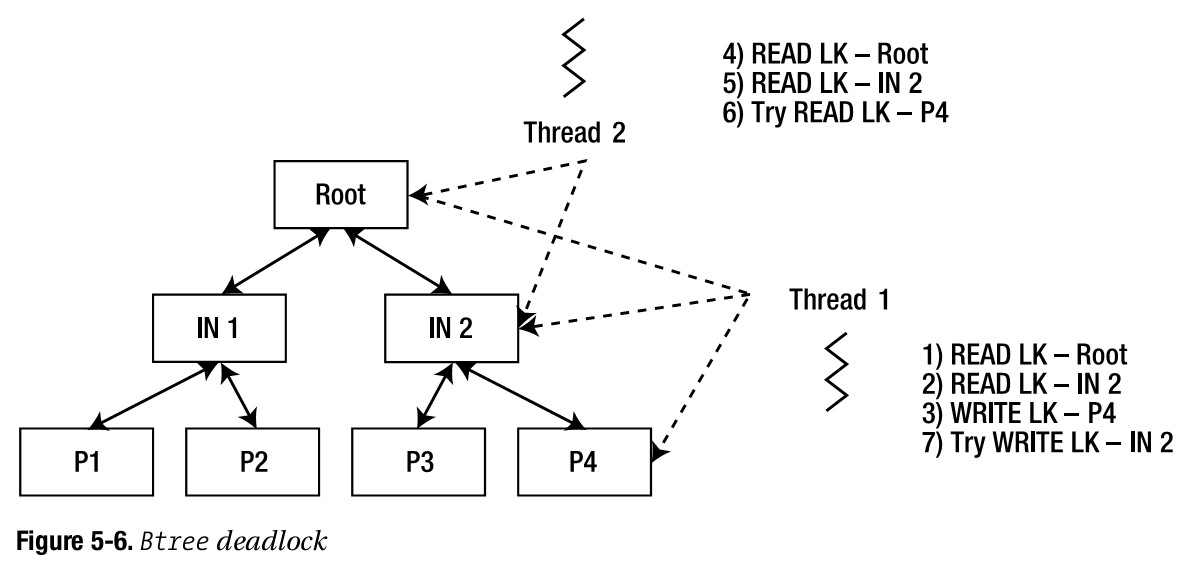
死锁检测(原理是遍历wait-for图,发现环;如果有环出现,则打破它):
- 同步检测 DB_ENV->set_lk_detect(),在每个阻塞的锁上检测,好处是立即发现,坏处是cpu占用略高(insignificant)
- 异步检测 DN_ENV->lock_detect() 或者 db_deadlock,需要额外发起一个进程或线程,坏处是只有当运行该命令时才能检测,好处是cpu占用低
一般解决死锁的办法:同步检测 + 异步检测 + 设置锁超时
当environment没有被损坏时,可以使用 db_stat -Cl 查看死锁情况。
Degree 2 isolation
degree 2 isolation 保证事务读到已经COMMIT的数据,但是在该读事务结束之前,其他事务可以修改该记录。degree 2 isolation适用于长时间的读取事务,比如遍历数据库等。
使用办法:使用 DB_TXN->txn_begin(), DB->get(), DBC->get() 等函数时,设置参数 DB_READ_COMMITTED。
区别于degree 3 isolation,后者保证在一个读事务内,无论读取多少遍,都可以读到同样的记录。但这会拒绝该记录的任何写事务。所谓degree 1 isolation则更进一步,可以读取未COMMIT的数据,建议谨慎使用,容易导致数据不一致。
性能调优和参数设置
lock table size
lock table的大小依赖于以下三个参数:
- lock最大数量:ENV->set_lk_max_locks() 同时可以请求的锁的最大值,比如同时2进程并发,要锁11个对象,则需要2x11个锁。
- locker最大数量:ENV->set_lk_max_lockers() 同时发起锁请求的最大值,比如同时2进程并发,则最多2个locker。
- lock object最大数量:ENV->set_lk_max_objects() 同时需要锁住的object的最大值,比如同时2进程并发,如果5层BTREE,则需要锁住2x5=10个对象,此外再加上单独的DB handle。
实际上面的计算得到的最大值还要double,因为如果开启deadlock检测,对每个locker来说BDB会新增一个dd locker,用于检测死锁。
timeout
可以分别设置锁和事务的超时:
- ENV->set_timeout() 设置锁和事务的默认超时
- DB_TXN->set_timeout() 单独设置事务的超时
cachesize
使用db_stat查看cache命中情况:
$ db_stat -h var -m
125MB 8KB Total cache size
1410M Requested pages found in the cache (99%)
14 Requested pages not found in the cache
建议根据程序设置合理的cachesize,尽量保证所有数据都可以被cache命中。
你是否需要BDB
可以看出BDB比一般的KV数据库还是要复杂很多的,如果你需要如下的一些特性,也许你可以考虑BDB:
- 期望对value部分也建立索引,比如需要secondary indices,多表之间join
- 多个进程并发读写数据库(但需要注意的是,在高并发情况下,比如8进程每秒1000读请求几条写请求,你在解决死锁问题上花费的时间也许会让你痛不欲生)
- 事务性、HA
如果你只需要一个简单有效的KV系统,leveldb也许是一个更好的选择,接口也更 modern 清晰简洁。
如果你只是单thread,那么BDB、sqlite等等,随便用什么都可以。