Dynamo是Amazon开发的一款高可用的分布式KV系统,已经在Amazon商店的后端存储有很成熟的应用。它的特点:总是可写(500+ per sec, 99.9% <300ms),并且可以根据需求优化配置(调整RWN模型)。
根据CAP原则 (Consistency, Availability, Partition tolerance),Dynamo是一个AP系统,只保证最终一致性。
Dynamo的三个主要概念:
- Key-Value:Key用来唯一标识一个数据对象,Value标识数据对象具体内容,只能通过Key对该对象进行读写操作。
- 节点(node):指一台物理主机。主要有 协调请求(request coordination)、成员及故障检测(membership and failure detection) 和 本地持久化(local persistence engine) 三大功能组件,底层的数据持久化存储一般使用Berkeley DB TDS。
- 实例(instance):每个实例由一组节点组成,从应用层看,实例提供IO功能。实例上的节点可以位于不同IDC以保证容灾。
数据分区(Partition)
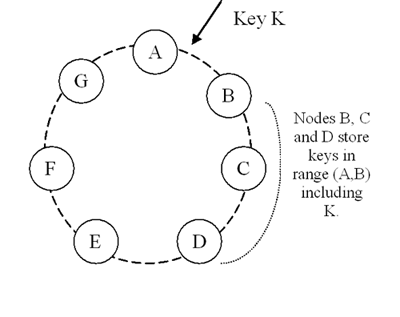
分布式系统中 数据分区 是个重要话题,Dynamo使用了Consistent Hash的变种,增加了虚节点的概念。这样一个实际的物理节点会分布到环上的成百上千个虚节点上。这样的好处在于:
- 如果一个节点不可用(故障或者维护),该节点的负载可以均匀的分散到其他可用节点上;
- 如果一个节点重新可用,或者新加入一个节点,新增节点可以接受到和原来节点大致相同的请求量;
- 虚节点的数目可以根据物理机器的容量调整,以保证不容量的机型达到相应的负载。
数据复制(Replication)
为了高可用性,Dynamo同样使用副本,默认副本数为3。Dynamo里复制副本很简单,当Key通过Consistent Hash散列到节点A上后,节点A的协调器(coordinator)会把该份数据自动复制到顺时针方向紧邻它的N-1个节点上,其中N是副本数。
数据版本(Data Versioning)
由于存在多副本,在没有达到最终一致性之前,对每个副本的写操作Dynamo是接受的,它的做法是标记一个版本号,这会导致系统中同一时间出现同一数据对象的多个版本。当然,这种做法比较适合Amazon自己的购物车应用,以便保证每次用户对购物车的更改都是可以保留下来。
在多数情况下,新版本会包含老版本,且系统自己就能协调(syntactic reconciliation)决定最终版本。但用过版本管理系统的人都知道,版本冲突是不可避免的,Dynamo也会遇到这种情况,此时需要交由应用层来协调,将多个分支的数据强行合并(collapse)一个版本。这种版本协调的结果,对于购物车应用来说,添加的商品不会丢失,但是删除的商品有可能出现,对于购物车场景来说是可以接受的。
Dynamo使用向量时钟(Vector Clock)来做版本控制,以合并冲突。

读写操作
Dynamo是一个高可用性系统,任何节点可以在任何时刻(failure-free)接受应用层的读写操作。但由于有多副本,读写操作就涉及数据一致性问题。为了解决该问题,Dynamo使用了类似法定仲裁Quorum的一致性协议。
Quroum协议有两个个配置项:
- R 一次成功读操作中最少参与的节点数目
- W 一次成功写操作中最少参与的节点数目
Quorum是说要保证:W+R > N,相当于 写成功需要的副本数 + 读成功需要的副本数 > 副本总数,则能保证最终一致性。官方建议(N, R, W) = (3, 2, 2)以兼顾AP。
故障处理(Hinted handoff)
在一个节点出现临时性故障时,数据会自动进入列表中的下一个节点进行写操作,并标记为handoff数据,在收到通知需要原节点恢复时重新把数据推回去。这能使系统的写入成功大大提升。
处理永久故障(Replica synchronization)
为了更快的检测副本之间是否不一致,Dynamo使用MerkleTree。MerkleTree是一个hash值构成的树,每个叶子节点是Key的hash值,然后中间节点是所有儿子节点的hash值,这样每个子节点的变动都会反应到上层父节点。使用MerkleTree为数据建立索引,只要任意数据有变动,都将快速反馈出来,可以提速数据变动时的查找。这一技术在torrent p2p传输中早有普及。
成员和故障检测
Gossip是一种去中心化的通讯协议,通常被用在分布式的非强一致性系统中,用来同步各节点状态。具体做法是,在一个有界网络中,每个节点会 周期性的 随机的 发起Gossip会话,经过多轮通信后,最终所有节点状态会达成一致。它可以用来发现成员,也可以用来故障检测。
Gossip有多种具体实现,Daynamo中使用的是Anti-entropy实现。
据说早期Dynamo的做法类似corosync,是在每台节点上维护一个全部节点状态的全局视图。