[TOC]
一个典型的数据科学处理流程长这样:
- 项目调研/数据收集
- 探索性分析
- 数据清洗
- 特征工程
- 模型训练(包括交叉验证和超参数的精调)
- 项目交付和见解
什么不是特征工程?
- 最初的数据收集
- 创造目标变量
- 数据清洗(移除重复变量、处理丢失的数据、修正遗失的标签等工作)
- 规则化或者归一化(交叉验证过程)
- 利用PCA选取特征(属于交叉验证过程)
有哪些特征工程方法?
- 交互特征,如特征相加、相减、相乘、相除
- 特征表示,如映射数值到分类(离散化)、合并稀疏特征(rare)
- 外部数据,如时间序列、地理编码、外部API(搜索、图像等)
- 错误分析,如误差分析、类型分割、非监督聚类(误分类的基础上)
数据清洗
缺失值的处理
针对缺失值常用的处理方法有:设置为均值、设置为众数、设置为Unknown等,或者这个样本不学习缺失特征的权重。
异常值检测和处理
通过特征取值的分布情况可以比较容易识别出异常的取值,取分位点做上下限截断以及对特征值做分桶后做值平滑是简单易操作的异常值处理方法。
特征处理(Feature Transform)
缩放(Scaling)
直接使用浮点数特征,如果不同特征取值范围差异很大可能会造成严重的过拟合,所以需要把不同特征的取值都映射到相同的范围内。
最常用的两种方法:
- min-max: $\frac{x – x_\min}{x_\max – x_\min}$ 。其中,$x_\min$是这个特征中的最小值,$x_\max$是这个特征中的最大值。适用于本来就分布在有限范围内的数据。
- z-score:$\frac{x – \mu}{\sigma}$。其中,$\mu$是这个特征的均值,$\sigma$是这个特征的标准差。适用于分布没有明显边界的情况,受outlier影响也较小。
【注】参考《广告点击率预测》 屈伟alex qu:如果在MR中计算均值和方差,可以使用公式 $Var(X) = E(X^2) - E(X)^2$,能够在一次MR中计算出整个数据的均值和方差。
此外,对特征属于power law分布的也可以取自然对数做比例缩放。
离散化(Discretization)
有时对浮点数特征做离散化后能获得更好的效果,例如将用户的年龄映射到“少年,青年,中年,老年”几个区间。对于取值分布稳定的特征,我们可以画出特征的分布图通过人工尝试多种区间划分方式。在常见的离散化方法中,因为互联网数据中的特征(如商品价格)的取值分布很多符合Power Law,所以一般通过Equal-Frequency分桶的到的特征比用Equal-Interval分桶得到的特征有更好的区分性。此外还有基于信息熵和假设检验等方法。
参考:http://breezedeus.github.io/2014/11/15/breezedeus-feature-processing.html
常见离散化的方法有等距和等频处理。
截断
一个网页可能属于多个分类(Category)或者多个主题(Topic),如果取值太多放入模型可能达不到预期的效果需要做截断。一般首先会对根据取值的权重(如属于某个分类的概率)排序,截断的方法有:
- 简单的取权重最大的前N个;
- 从权重最大的开始往下取,当累积的权重达到一定阀值停止;
- 当前后两个取值的权重比值超过一定阀值时终止;
- 前面三种方法组合使用;
二值化(Binarization)
通过one hot encoding可以把有$N$个取值的离散特征变成$N$个二值特征。
Embedding
Facebook:利用决策树Split点作为离散化的点(参考GBDT+LR) 百度:利用DNN模型做Embedding
特征选择(Feature Select)
Filter、Wrapper、Embedded三种方法各有不同,但没有孰好孰坏之分,在我们的实际工作中会结合使用。
- Filter作为简单快速的特征检验方法,可以指导特征的预处理和特征的初选。
- Embedded特征选择是我们学习器本身所具备的能力。
- 通过Wrapper来离线和在线评估是否增加一个特征。
Filter
Filter这类方法是选定一个指标来评估特征,根据指标值来对特征排序,去掉达不到足够分数的特征。这类方法只考虑特征X和目标Y之间的关联。
统计视角:
- 相关系数(Correlation)
- 假设检验(Hypothesis Testing)
信息论视角:
- 互信息(Mutual Information)
- 信息增益(Information Gain)
- 最小描述长度(Minimum Description Length)
Wrapper
Wrapper方法和Filter不同,它不单看特征X和目标Y直接的关联性,而是从添加这个特征后模型最终的表现来评估特征的好坏。Wrapper方法需要选定一种评估模型效果的指标,如Area Under the Curve (AUC)、Mean Absolute Error (MAE)、Mean Squared Error(MSE)。
参考统计学里模型选择的stepwise方法。
离线评估结果是重要的参考指标,但在实际应用中,往往最终还是通过线上A/B Test实验来判断一个特征的效果。
Embeded
Filter方法和Wrapper方法都是和分类算法本身的实现无关,可以与各种算法结合使用。而Embedded特征选择方法与算法本身紧密结合,在模型训练过程中完成特征的选择。例如:决策树算法每次都优先选择分类能力最强的特征;逻辑回归算法的优化目标函数在log likelihood的基础上加上对权重的L1或者L2等罚项后也会让信号弱的特征权重很小甚至为0。
其他事项
特征穿越
特征穿越现象是指用未来发生的某个信号来训练模型,再用来评估结果,导致模型线下评估效果非常好,但线上无效。
在做特征重要性分析的时候,如果某个特征的重要性极高,那应该评估一下是不是有穿越的现象了。
举个例子:CTR模型用到了用户画像特征,该数据是用最近一个月的点击数据训练得来的,而且只有当天的全量而并不是按天切片的,这意味着如果和一个月前的其他数据join到一起的话,这部分用户画像特征就穿越了。因为它用到了这段时间之后的数据,再用它来训练模型是不合适的。
工业界LR特征做法
一般亿级别的特征是挑选以后的,原始特征特征会更多一些。由于数量太大,离散,特别稀疏,一般不用传统的PCA来挑选特征。主要的挑选方法有几种: 1, 基于特征出现的频率,频率特别低的不要,因为它影响到的数据也少。2,看效果比如AUC值,新加入的一批特征如果没有带来AUC提高,就别加了。2是最主要的。
广告模型中逻辑回归一般用高纬度的one hot特征,特征值只有0和1两种。离散的类别特征很好处理,实数型连续值特征需要特殊处理,比如分筒,决策树分筒不错,自动学threshold, 而且还能学特征间的相互关系,帮助做特征工程。
标准化 Normalization
什么时候必须对数据做Normalization?主要看模型是否具有 伸缩不变性。
有些模型在各个维度进行不均匀伸缩后,最优解与原来不等价,例如SVM。对于这样的模型,除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据dominate。
有些模型在各个维度进行不均匀伸缩后,最优解与原来等价,例如LR。对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太“扁”,迭代算法可能收敛得很慢甚至不收敛。所以对于具有伸缩不变性的模型,最好也进行数据标准化。 :smile:
参考:http://www.win-vector.com/blog/2011/09/the-simpler-derivation-of-logistic-regression/ 最后的结论:coordinate-free。
标准化之前:
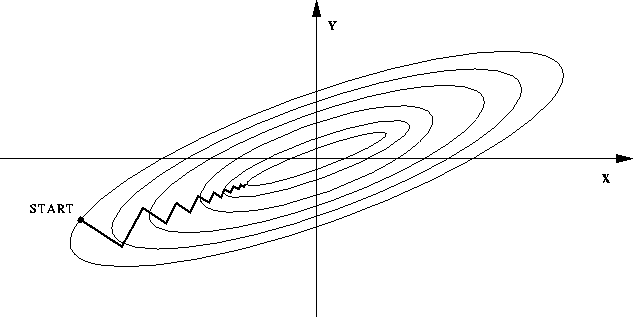
标准化之后: