Tornado框架算是很轻量级的 单线程 异步 编程框架,只是额外加了很基础的模板、HEADER、COOKIE、路由等的WEB相关的支持(都定义在web.py里),它的大部分代码是在封装nonblocking socket、epoll、event loop等基础的异步编程模块。所以,在使用tornado之前一定要先了解这个框架的定位,它不单能够用于WEB服务编程,也非常适用于需要异步编程的后台服务。
tornado框架
Tornado框架的编码水准很高,虽然不了解tornado源码不妨碍使用,但深入了解一下还是有助于提高自己的PYTHON水平的,这里有一份源码详解。
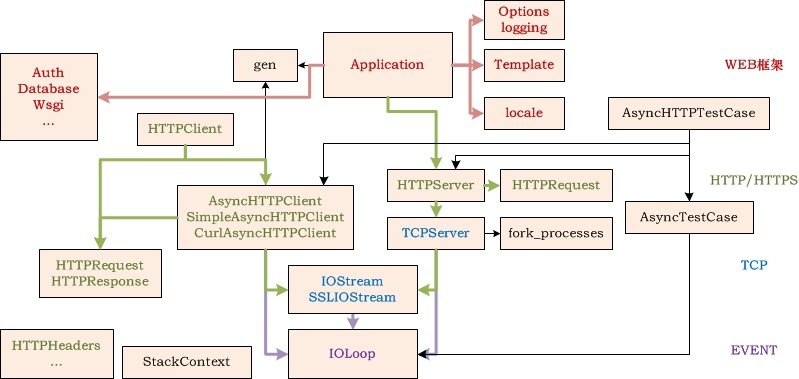
从这个框架图也能看出,tornado 完整地实现了HTTP服务器和客户端,在此基础上提供WEB服务。它可以分为四层:
- 最底层的EVENT层处理IO事件(ioloop.py 和 iostream.py,以及platform相关);
- TCP层实现了TCP服务器,负责数据传输(tcpserver.py);
- HTTP/HTTPS层基于HTTP协议实现了HTTP服务器和客户端(httpserver.py);
- 最上层为WEB框架,包含了模板、认证、本地化等等WEB框架所需的功能(web.py、auth.py、template.py等)。
在TCP层使用tornado,可以从TCPServer派生,但是IO方面需要做进一步处理。示例:
class EchoServer(netutil.TCPServer):
def handle_stream(self, stream, address):
self._stream = stream
self._read_line()
def _read_line(self):
self._stream.read_until('\n', self._handle_read)
def _handle_read(self, data_in):
self._stream.write('You sent: %s' % data_in)
self._read_line()
server = EchoServer()
server.listen(12345)
ioloop.IOLoop.instance().start()
在HTTP/WEB层使用tornado,可以借助Application类,也是我们常用的开发方式。示例:
application = web.Application([
(r"/", MainPageHandler),
])
server = httpserver.HTTPServer(application)
server.listen(8080)
ioloop.IOLoop.current().start()
异步
Tornado虽然是一个异步框架,但是如果使用不当很容易造成性能低下。需要理解一下服务并发量、吞吐量、响应时间这些衡量指标,异步并不能保证这些指标优秀,异步只是指任务不被线性执行。最常见的是如果你在tornado进程里执行一条耗时很长的MySQL查询操作,同样会block住整个tornado进程,而tornado是单线程框架,这意味着block住了该线程上的所有其他请求。
要用好tornado的异步能力,需要掌握内置的异步模块和celery。
web.asynchronous
装饰器 web.asynchronous 只能用在verb函数之前(即get/post/delete等),并且需要搭配tornado异步客户端使用,如httpclient.AsyncHTTPClient。加上这个装饰器后,必须在异步回调函数里显式调用 RequestHandler.finish 才会结束这次 HTTP 请求。
tornado里大多的异步函数,包括web.asynchronous都会用到future特性。如果用到了内置的 concurrent.Future,需要注意该类不是线程安全的。
gen模块
gen是tornado异步支持的核心模块。
装饰器 gen.coroutine 可以把web.asynchronous装饰的多个分散的异步函数调用写成coroutine的形式,回调函数的结果直接用yield返回。这种用法的优势就不赘述了,目前基本已经在各种主流语言普及了。在版本3.1之后,可以直接省略web.asynchronous改用gen.coroutine替代。
函数 gen.Task 是另外一个在coroutine里使用异步函数的辅助函数,它可以把一个带callback参数的异步调用包装起来,该异步调用传给callback函数的参数将作为yield的返回值。如果传给callback函数的是多参数,会返回一个简单的Argument对象。这里没有cencept定义理解起来可能有些费劲,下面是个示例,运行一遍有助于理解:
import tornado.web
import tornado.gen
import logging
def echo(message, callback):
callback(message, 'that is callback message')
@tornado.gen.coroutine
def test():
response = yield tornado.gen.Task(echo, 'this is first message')
logging.warn(response.args[1])
test()
如果coroutine函数需要返回,需要借助 gen.Return,类似这样: raise tornado.gen.Return(XXX),捕捉这个异常得到返回值。
celery
上面所有的异步调用只使用到了内置的异步客户端httpclient.AsyncHTTPClient,可以参考一下,如果要自己写一个异步客户端还是比较麻烦的。比如,你的函数里包括了一个同步MySQL调用,那么不管你怎么加装饰器,还是yield返回都是没用的,因为你的MySQL调用本身是同步的。可以参考AsyncHTTPClient,借助tornado.ioloop.IOLoop封装一个异步的MySQL客户端,但成本还是很高的。
所幸我们可以借助celery项目,这是一个分布式的任务队列。tornado接到请求后,可以把所有的复杂业务逻辑处理、数据库操作以及IO等各种耗时的同步任务交给celery,由这个任务队列异步处理完后,再返回给tornado。这样只要保证tornado和celery的交互是异步的,那么整个服务是完全异步的。
Tornado和celery的交互可以借助 tcelery 这个适配器。
具体实现可以借助gen模块,这里是个示例:
@tornado.gen.coroutine
def get(self, *args, **kwargs):
response = yield tornado.gen.Task(example_task.apply_async, args=[self.request.arguments])
self.finish(response.result)
上面也说了gen.Task会给传入的example_task.apply_async添加一个callback参数,默认celery的apply_async函数是不认识这个参数的,而tcelery的功能就是对这俩做了适配,让gen.Task和apply_async无缝工作。目前tcelery应该只支持amqp backend。
开发部署
可以使用supervisord启动tornado。1
使用nginx做负载均衡,此时建议给HTTPServer传递参数 xheaders=True。2
调试
开发的时候如果想直接看到改动效果,而不是每次改完还要重新启动python进程,可以借助 tornado.autoreload 模块:
python -m tornado.autoreload server.py
同时给Application传递如下参数:
debug=True
autoreload=True
compiled_template_cache=False
static_hash_cache=False
serve_traceback=True
对于一些超时的调用直接打印出调用堆栈:
IOLoop.instance().set_blocking_log_threshold(0.050) # 当IOLoop阻塞50ms会打印调用栈
其他
常用工具类
tornado.options
tornado.log 有三个内置的log: access_log、app_log 和 gen_log。
sqlalchemy
tornado里使用sqlalchemy,参考手册 ORM 2.6.9 Contextual/Thread-local Sessions 这一章。保证one session one request即可。