传统搜索广告召回
为了兼顾效果和性能,一般分为QR(Rewriting)和检索(Ad-selecting)两部分。
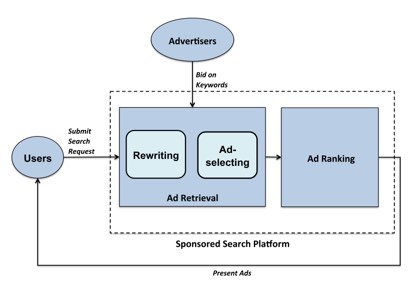
- QR主要考虑query和bidword的文本相关性,目标并非优化RPM/CTR。
- 索引依赖bidword。但受限于市场信息的缺失和投放管理的成本,广告主有时并不能及时准确地为自己的广告选择出最合适的bidword。
- 检索出于性能考虑,使用简单规则而不会用复杂的模型。比如BS。
传统搜索广告召回仅由query触发,并未考虑用户画像,长期、实时点击偏好等信息。这些个性化signal其实也有助于更好的理解user intention。
相关工作
QR
- 解决query过短问题:伪反馈,外部资源,landing page
- 利用session数据,利用点击二部图(simrank++)
- MT、SMT、NMT
伪相关反馈,参考《信息检索导论》第九章。
检索
- WAND
- 各种索引技巧
智能检索模型
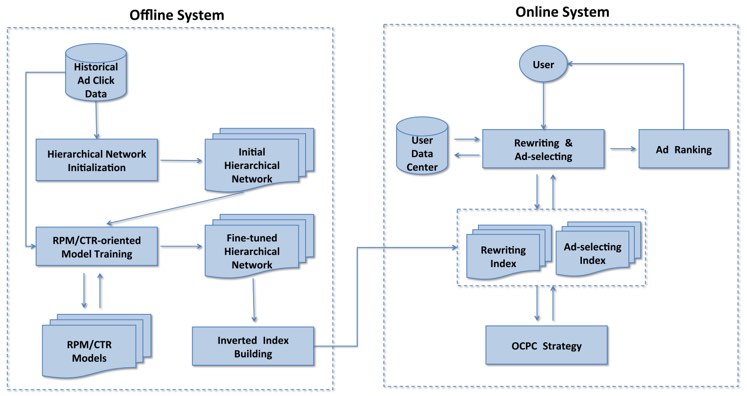
3232 3种node、2种edge、3种init、2份index
3种node:
- signal Query、用户画像、长期点击、实时点击
- key Query、Item、Shop、Brand,可以看作是ad properties,类似我们的node,用来表达ad
- ad
2种edge:
- Rewriting QR,把signal改写到key
- Ad-selecting 检索,从key查询到ad
3种init方法初始化层次图:
- Click Counts 利用点击数据关联node(threshold),依赖曝光量
- Information Value 特征选择工具,用于筛选比较重要的node
- Session-based 利用session计算相关性
2份index:
- Rewriting index signal->key
- Ad-selecting index key->ad
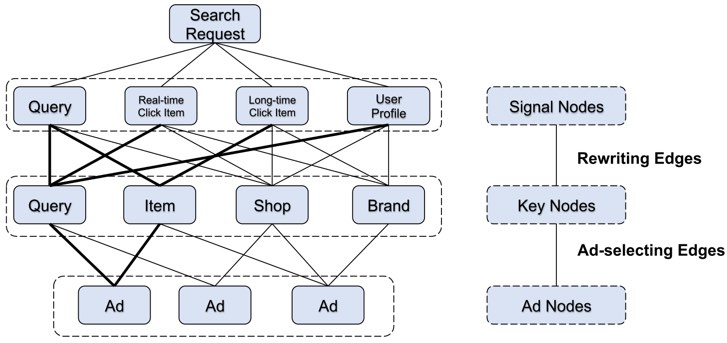
初始化图
因为只会初始化图一次,后续都只在这张图上迭代,所以会利用不同的方式在不同node之间建立edge,把图尽量填得很稠密。
训练模型
图的结构是固定的,模型的目的是给edge打分,所以可以用不同的特征和算法来训练模型。
原始数据还是利用历史点击数据,技巧是把一条样本 <{signal}, ad, label> 根据图扩展成多条样本(路径) <{signal-key}, {key-ad}, label>,在此基础上再构造特征。
为了性能考虑,只使用LR、GBDT和三层MLP等比较简单的算法,effectiveness vs efficiency trade-off贯穿这篇论文或者说检索主题。
根据不同算法使用Sparse和Continuous两种特征。
美容养生 -> 紫琪尔国际丰胸美胸机构, 1
美容养生 -> SPA, SPA -> 紫琪尔国际丰胸美胸机构, 1
signal: t1, t2; key: t3; ad: poi id p4, category id c5 ... 1
模型predict的结果即一条路径的weight。
如果目标是RPM,则使用price作为每份样本权重。
索引结构
维护两份索引:
signal: t1 -> key: t3, weight: 0.3
key: t3 -> ad: p4, weight: 0.3
可以得到每条edge的得分,用作检索海选的排序。
效果
CTR+2% RPM+8% PR+1.2%
参考
- https://yq.aliyun.com/articles/351828
- Yan, S., Lin, W., Wu, T., Xiao, D., Wu, B., & Liu, K. (2017). Beyond Keywords and Relevance: A Personalized Ad Retrieval Framework in E-Commerce Sponsored Search. Retrieved from http://arxiv.org/abs/1712