代码 https://github.com/tomwhite/hadoop-book
【第二章】MapReduce简介
mapreduce是一种可用于数据处理的编程模型,它是并行运行的,可以处理大规模数据分析。
节点角色:
- tasktracker:用来执行map和reduce任务
- jobtracker:用来调度任务在哪个tasktracker上执行
执行任务期,tasktracker会将运行进度报告给jobtracker,job由此记录作业的整体进度,如果其中一个任务失败,它可以调度别一个tasktracker来重新执行。
分片(split):hadoop将mapreduce输入数据划分成等长的小数据块称为 分片,hadoop为每个分片建立一个map任务,并由map函数来处理分片中的每行数据(分片切分更细,负载均衡就越好,当然太小map数就越多,所须要执行时间就越长)
一个合理的分片应该与hdfs块大小相同,默认64M。
map函数的输出会写到磁盘上,非hdfs;reduce的输出存在hdfs上实现可靠存储。
单个reduce的输入通常来自所有map的输出。
【第三章】HDFS分布式文件系统
Hadoop有一个文件系统抽象: org.apache.hadoop.fs.FileSystem
HDFS只是其中的一个实现: org.apache.hadoop.hdfs.DistributedFileSystem
HDFS对外的接口有很多,如shell、thrift、webdav、http、ftp以及Java接口。
【注】ftp接口很方便,允许FTP客户端和HDFS进行数据传输。
Java接口
可以直接使用FileSystem API读取或写入HDFS文件,示例:
public class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
FileSystem fs = FileSystem.get(URI.create("hdfs://path/to/file"));
InputSystem in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
调用该Java接口:
$ hadoop FileSystemCat hdfs://path/to/file
数据流
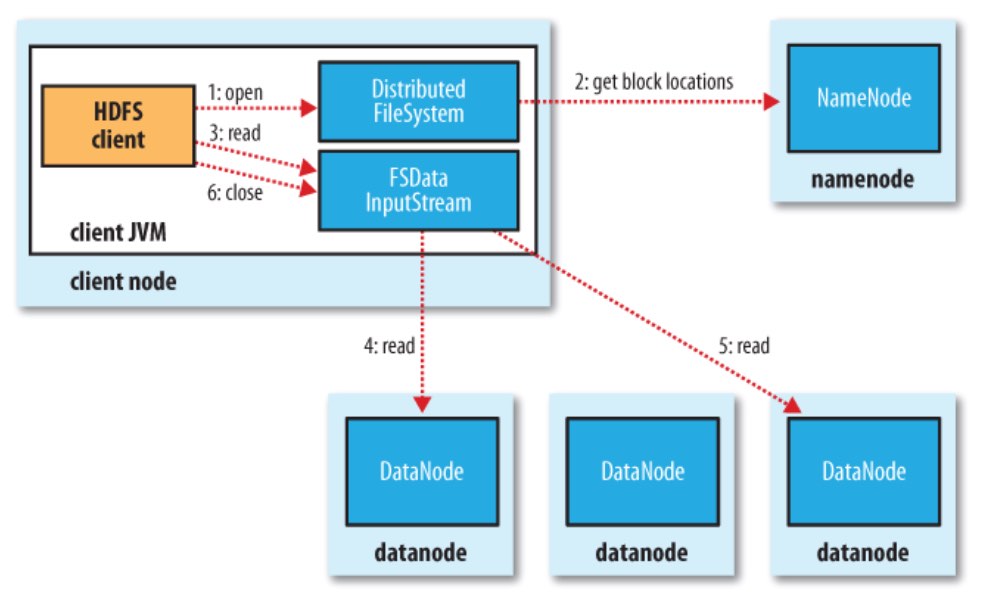
1)客户端从HDFS中读取文件
2)客户端对HDFS写入数据
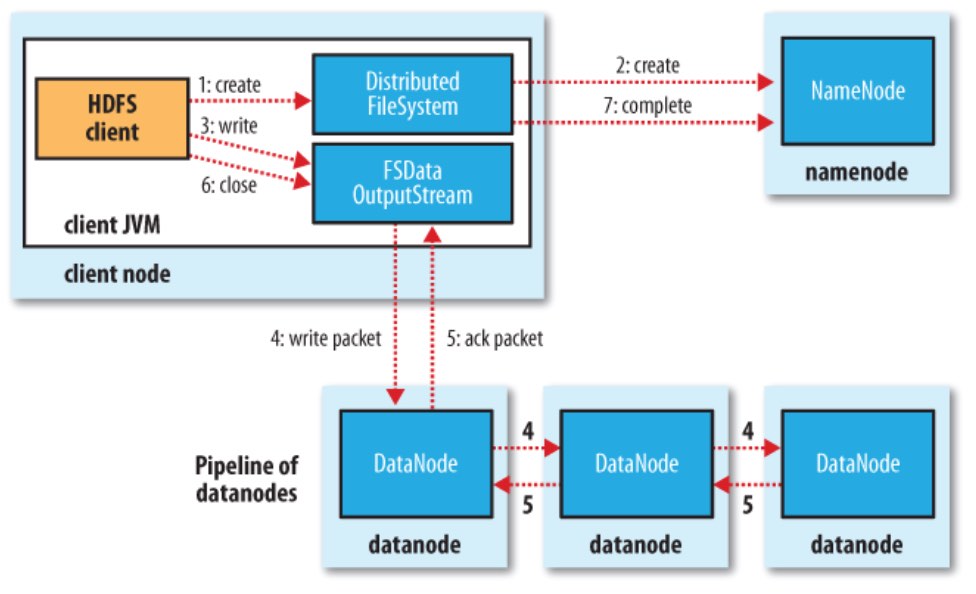
集群之间的数据复制使用 distcp,实际是启动MR作业执行:
$ hadoop distcp hdfs://namenode1/foo hdfs://namenode2/bar
【第四章】Hadoop的I/O
压缩
org.apache.hadoop.io.compress.GzipCodec
可以在MR任务里设置输出的压缩方式:
conf.setBoolean("mapred.output.compress", true);
conf.setClass("mapred.output.compression.codec", GzipCodec.class, CompressionCodec.class);
在map作业里也启用gzip压缩:
conf.setCompressMapOutput(true);
conf.setMapOutputCompressClass(GzipCodec.class);
序列化
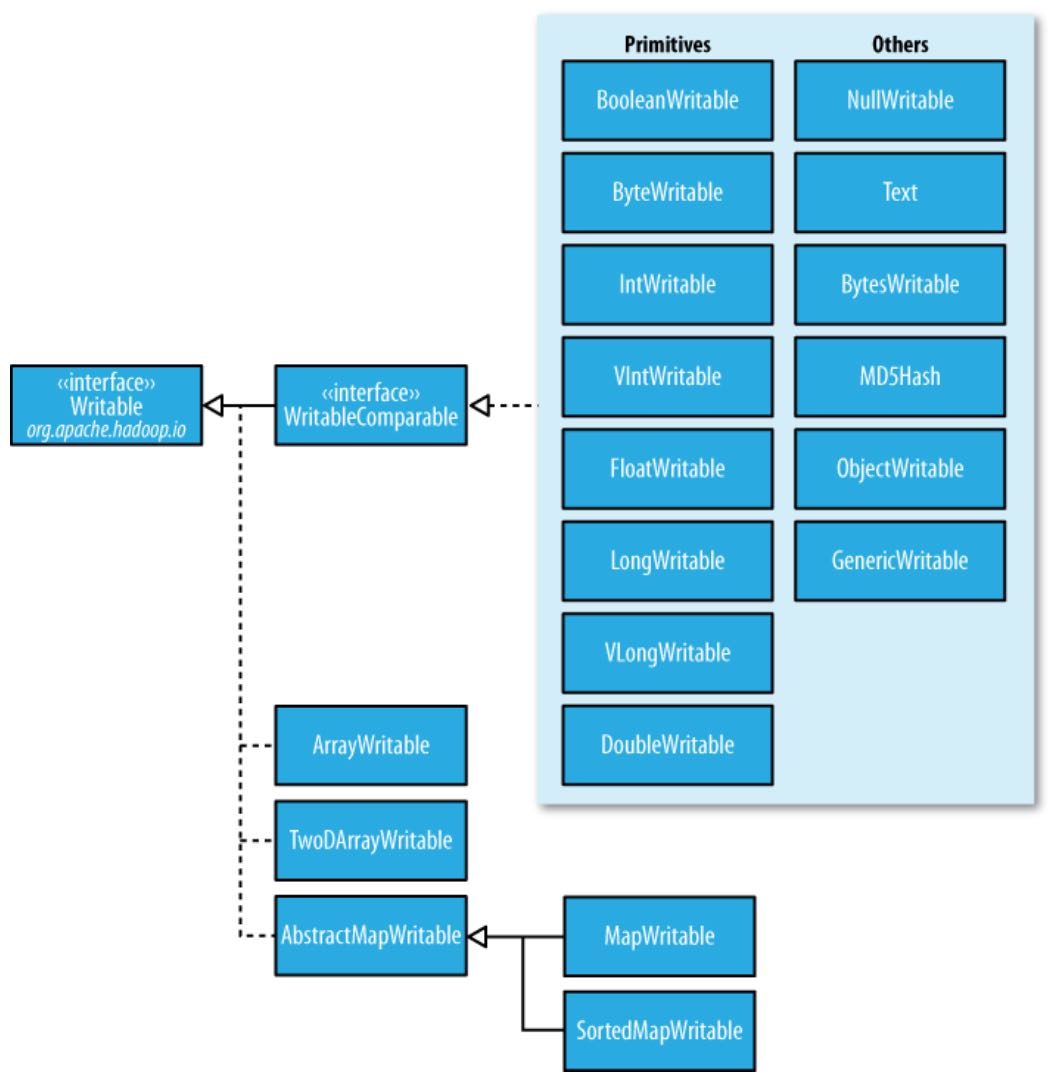
自定义Writable:
public class TextPair implements WritableComparable<TextPair> { }
基于文件的数据结构
SequenceFile 用于存储二进制键值对。
writer = SequenceFile.createWriter(...);
writer.append(key, value);
MapFile 是排序过且带索引的SequenceFile。
【第五章】MapReduce应用开发
Hadoop API配置由 org.apache.hadoop.conf.Configuration 维护,可以在xml资源文件里定义各种配置信息。
比如,一个配置文件 configuration-1.xml:
<?xml version="1.0"?>
<configuration>
<property>
<name>size</name>
<value>12</value>
<description>Size</description>
</property>
</configuration>
然后,可以在java里获取这个配置:
Configuration conf = new Configuration();
conf.addResource("configuration-1.xml");
assertThat(conf.getInit("size", 0), is(10));
【注】如果Hadoop用户身份和客户端机器上用户名不同,可以通过设置 hadoop.job.ugi 属性,显示设置Hadoop用户名和组名。比如可以设置为 hive,hive,用户名和组名以逗号分隔。(系统没有身份验证,这个YARN里会修复)
【第六章】 MapReduce工作机制
工作角色
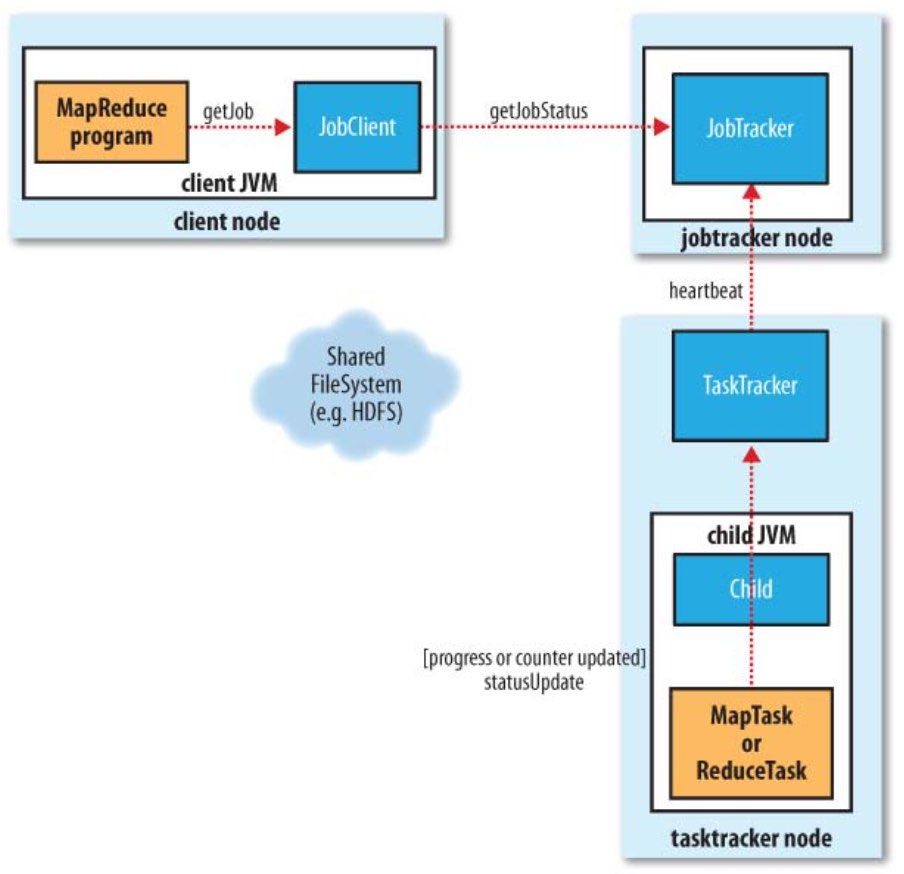
- client:用于提交作业
- jobtracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业。jobtracker是一个java应用程序,主类是JobTracker
- tasktracker:保持JobTracker通信,在分配的数据片段上执行MapReduce任务。tasktracker是一个java应用程序,主类是TaskTracker
- HDFS,用于在其他实体间共享作业文件。
工作流程
0)提交作业
- 在作业提交之前,需要对作业进行配置
- 程序代码,主要是自己书写的MapReduce程序。
- 配置输入输出路径
- 其他配置,如输出压缩等。
- 配置完成后,通过JobClinet.submitJob()来提交
1)作业初始化
JobTracker收到submitJob()的请求后,会把job放入一个内部队列,作业调度器会负责调度并初始化。默认的调度方法是FIFO调试方式。 具体会根据数据分片创建map任务,根据mapred.reduce.tasks值创建reduce任务,同时还有额外两个任务:作业建立任务和作业清理任务(由tasktracker运行)。
2)任务分配
- TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。
- TaskTracker会主动向JobTracker询问是否有作业要做,如果自己可以做,那么就会申请到作业任务,这个任务可以使Map也可能是Reduce任务。
3)执行任务
TaskTracker申请到任务后,会做如下事情:
- 拷贝代码到本地;
- 拷贝任务的信息到本地;
- 启动JVM运行任务。
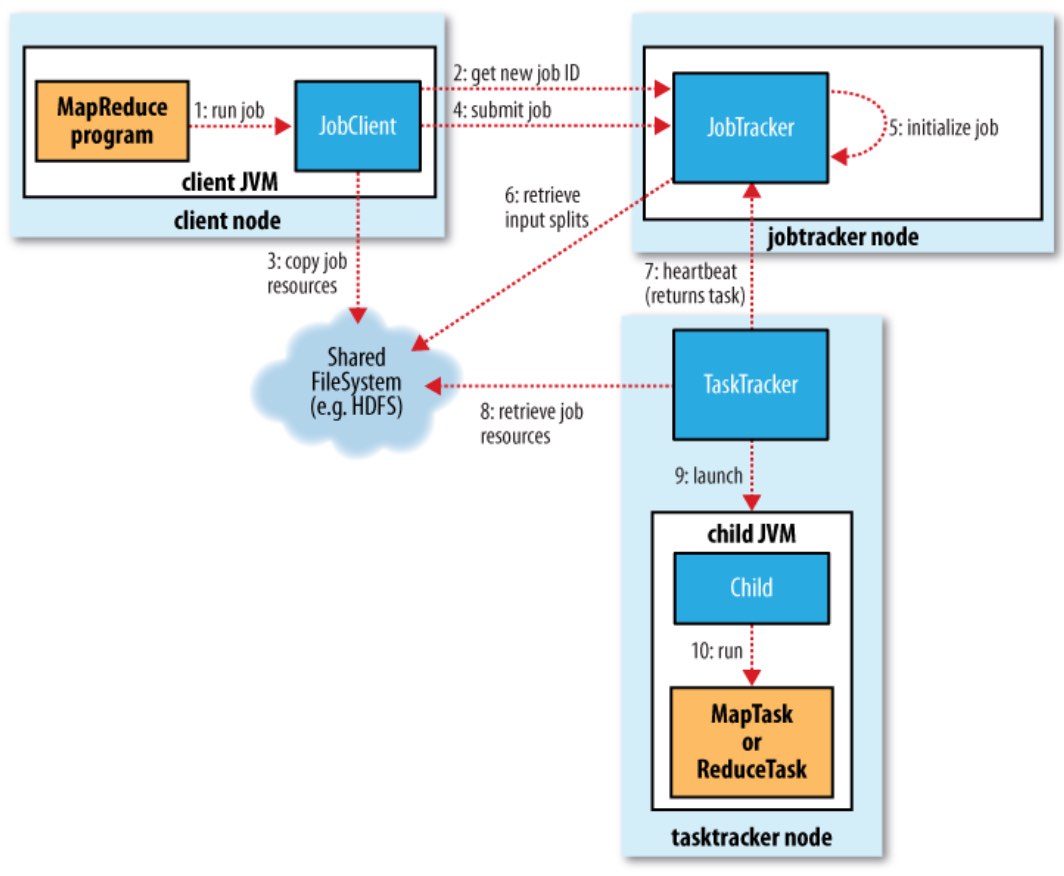
4)进度和状态更新
- 任务在运行过程中,首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。
- 任务进度是通过计数器来实现的。
5)Streaming和Pipes
Streaming和Pipes都是运行特殊的map和reduce任务来运行用户提供的可执行程序,并与其进行通信。
Streaming任务会利用标准输入输出流与进程通信。另一方面,Pipes任务监听socket并发送该环境的一个端口号给c++进程,这样在开始时,c++进程就建立了一个与父java Pipes任务的持久化socket链接。
两种情况下,java进程都会在任务执行时把输入键值对发送给外部进程,由外部进程运行用户定义的map和reduce方法,然后把输出键值对传回给java进程。从tasktracker来看,这好像是在子进程中运行了map和reduce代码。
6)作业完成
Jobtracker收到最后一个任务(这是一个特殊的作业清理任务)的完成通知后,辨别作业状态改为“成功”。然后当作业查询状态的时候,就会知道作业已完成,然后打印信息通知用户,返回waitForCompletion()。作业统计与计数值会打印到控制台。
Jobtracker还会发送一个http作业通知(如果配置了的话)。可以通过job.end.notifucation.url属性来配置。
最后,jobtracker清理掉他的工作状态,叫tasktracker也做一样的工作(如清空中间输出)。
错误处理
1)任务失败 MapReduce在设计之初,就假象任务会失败,所以做了很多工作,来保证容错。(Design for failure) 一种情况: 子任务失败,另一种情况:子任务的JVM突然退出,这都会导致任务的挂起。
2)TaskTracker失败
- TaskTracker崩溃后会停止向Jobtracker发送心跳信息。
- Jobtracker会将该TaskTracker从等待的任务池中移除。并将该TaskTracker上的任务,移动到其他地方去重新运行。
- TaskTracker可以被JobTracker放入到黑名单,即使它没有失败。
3)JobTracker失败 单点故障,Hadoop新的0.23版本解决了这个问题。
作业调度
1)FIFO
Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业。
2)公平调度器
为任务分配资源的方法,其目的是随着时间的推移,让提交的作业获取等量的集群共享资源,让用户公平地共享集群。具体做法是:当集群上只有一个任务在运行时,它将使用整个集群,当有其他作业提交时,系统会将TaskTracker节点空间的时间片分配给这些新的作业,并保证每个任务都得到大概等量的CPU时间。
3)容量调度器
支持多个队列,每个队列可配置一定的资源量,每个队列采用 FIFO 调度策略,为 了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交 的作业所 占资源量进行限定。调度时,首先按以下策略选择一个合适队列:计算每个队列中 正在运行的任务数与其应该分得的计算资源之间的比值,选择一个该比值 最小的队 列;然后按以下策略选择该队列中一个作业:按照作业优先级和提交时间顺序选择 ,同时考虑用户资源量限制和内存限制。但是不可剥夺式。
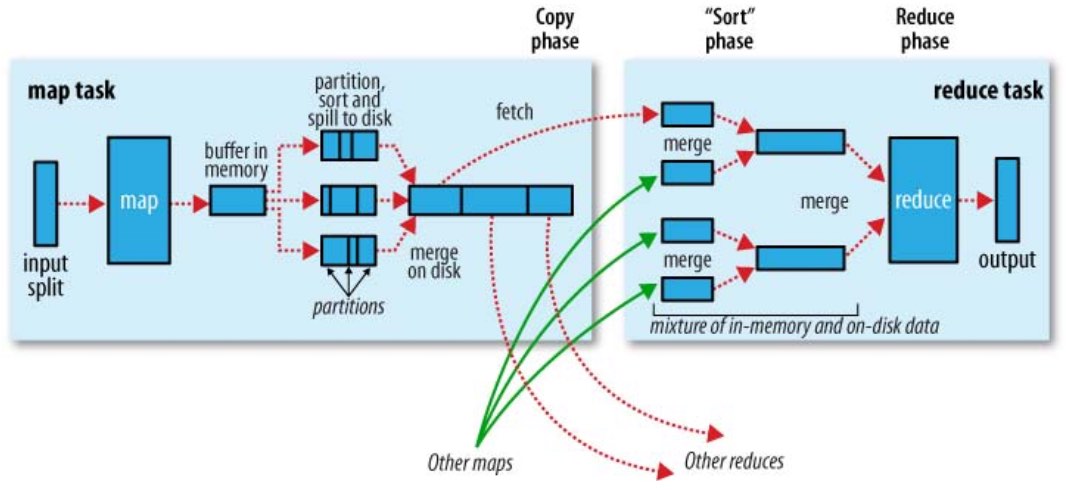
Shuffle与排序
Mapreduce 的 map 结束后,把数据重新组织,作为 reduce 阶段的输入,该过程称 之为 shuffle(洗牌)。
而数据在 Map 与 Reduce 端都会做排序。
Map
- Map 的输出是由collector控制的
- 主要代码在collect函数
Reduce
- reduce的Shuffle过程,分成三个阶段:复制Map输出、排序合并、reduce处理。
- 主要代码在reduce的run函数
任务的执行
1)推测式执行
每一道作业的任务都有运行时间,而由于机器的异构性,可能会会造成某些任务会比所有任务的平均运行时间要慢很多。这时MapReduce会尝试在其他机器上重启慢的任务。为了是任务快速运行完成。该属性默认是启用的。
2)JVM重用
启动JVM是一个比较耗时的工作,所以在MapReduce中有JVM重用的机制。条件是统一个作业的任务。
可以通过 mapred.job.reuse.jvm.num.tasks 定义重用次数,如果属性是-1那么为无限制。
3)跳过坏记录
数据的一些记录不符合规范,处理时抛出异常,MapReduce可以讲次记录标为坏记录。重启任务时会跳过该记录。默认情况下该属性是关闭的。
4)任务执行环境
Hadoop为Map与Reduce任务提供运行环境。
如:Map可以知道自己的处理的文件
问题:多个任务可能会同时写一个文件
解决办法:将输出写到任务的临时文件夹。目录为:{mapred.out. put.dir}/temp/${mapred.task.id}
【第七章】 MapReduce类型和格式
输入格式
When a hadoop job is run, it splits input files into chunks and assign each split to a mapper to process. This is called Input Split
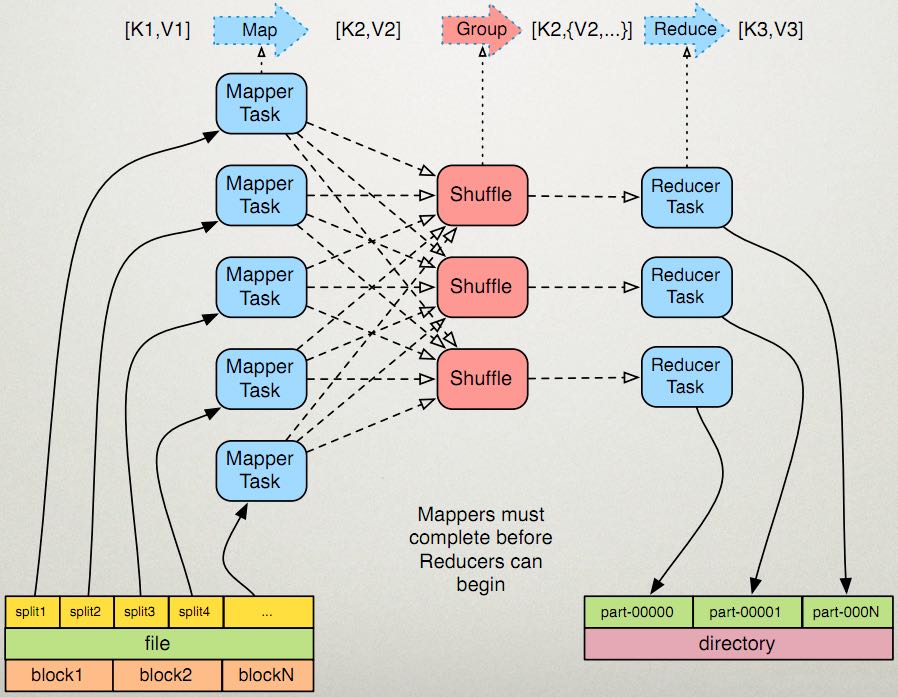
分片(split)的概念在开发MR程序时非常重要,由InputSplit类定义,应该阅读相关代码才能理解深刻: