rabit库
实现了MPI的主要功能:Allreduce和Broadcast,此外还提供了:容错性(Fault Tolerance)和可恢复性(Recovery)。
Allreduce
http://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/
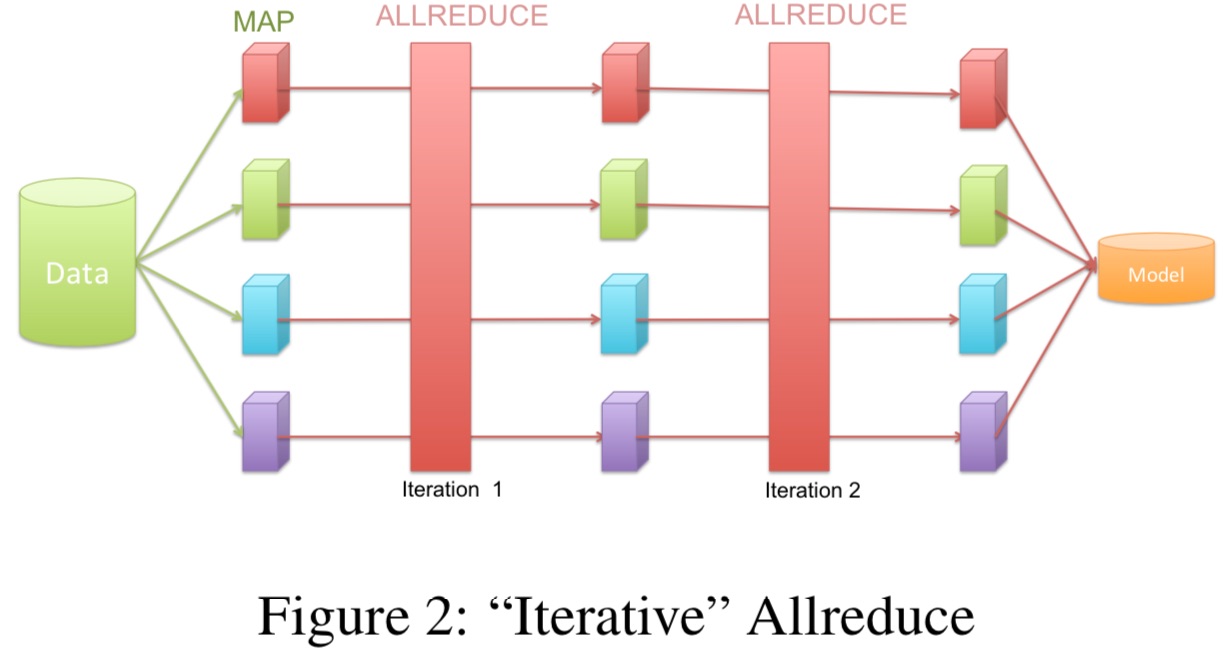
Allreduce类似reduce,区别是不指定主线程,而是把reduce结果返回给所有线程。
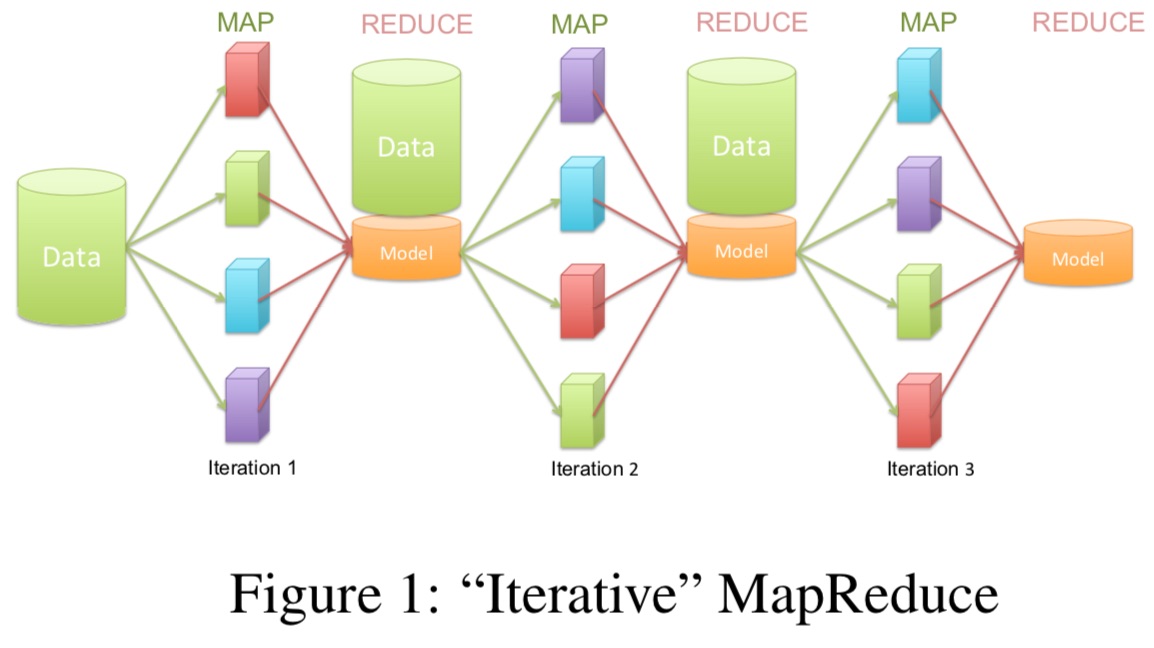
Allreduce相较于mapreduce,通过允许程序员轻松的将模型(这些模型将被复制于每个节点)维护于内存中,使它避免了不必要的map过程、重新分配内存步骤以及迭代器之间的硬盘读写过程。
Broadcast
http://mpitutorial.com/tutorials/mpi-broadcast-and-collective-communication/
Broadcast比循环Send/Recv数据效率更高,等价于在主线程里Send数据,然后在其他线程里Recv数据。
每个节点向上传递自己的值,每个节点执行一次求和操作,直到根节点,这就是Allreduce过程;根节点告诉所有叶子节点结果,这就是Broadcast过程。
论文里称作Message Passing?
容错性和可恢复
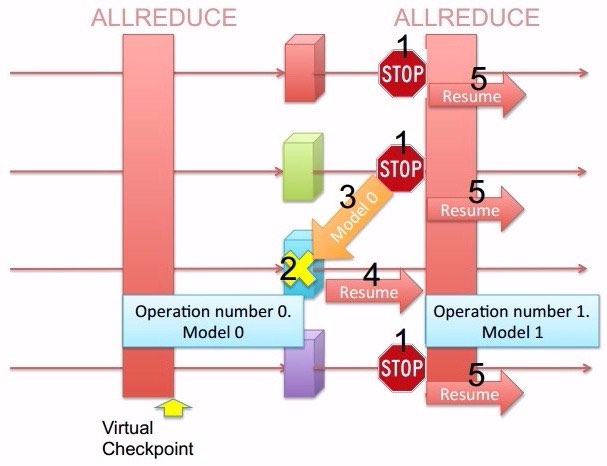
rabit提供的容错性基于两个主要协议:一致性协议(consensus)和路由协议(routing),如图从1到 5是其执行步骤:
- 暂停所有节点直到失败节点完全恢复;
- 通过min运算检测需要恢复的模型版本(consensus - allreduce);
- 从最近的节点传输模型到失败节点(routing - broadcast);
- 失败节点利用收到的模型继续执行;
- 当失败节点恢复后,其他节点继续执行。
容易理解,当蓝点down 机后,所有节点在下一个Allreduce前等待该节点恢复,在蓝点启动后,从最近相邻节点读取模型,然后和其他节点一同继续下去。 那么,是如何得知哪个节点down了呢,就是通过模型版本加前面提到过的Allreduce,这里采用了一个一致性协议,协议规定所有模型的版本必须一致,版本号根据Allreduce轮数依次增加,所以找到有版本号比大家低的,就说明那个节点down掉了,恢复即可。
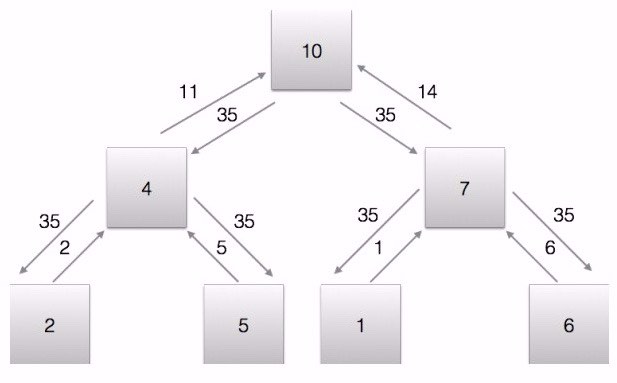
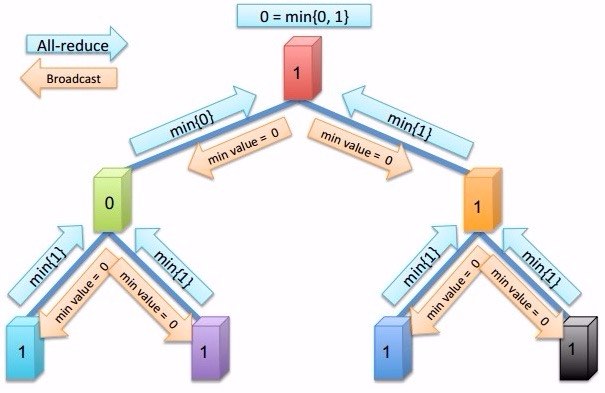
寻找不一致的version,即一致性协议,利用min运算做allreduce。如图所示:
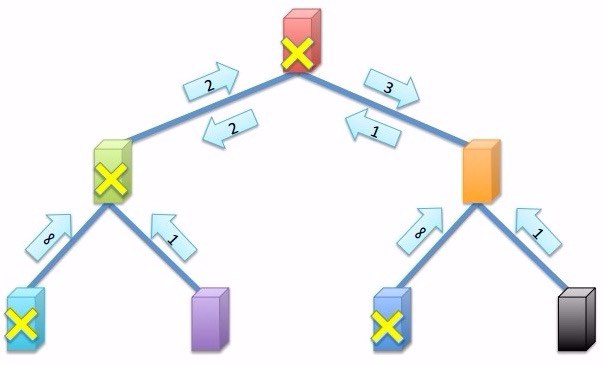
选择最近节点,是一个最短路径问题,即路由协议,两轮broadcas。如图所示,先计算失败节点到最近的有模型的节点的距离,再拉取模型(不在图里):
对比测试
Amazon EC2 32节点
和MPI
broadcast吞吐量只有MPI的一半,但MPI没有容错,且优化很多年了。
和Spark mllib
kmeans:2M样本,500K词,当k=5时,rabit训练时间是mllib 6倍的速度,更高的k时,mllib直接oom了;而k=64时,rabit依然是k=5 mllib两倍的速度。
参考
- RABIT: A Reliable Allreduce and Broadcast Interface, TianQi Chen, 2015