[TOC]
内存寻址
逻辑地址
逻辑地址(logical address):在机器语言中指定一个操作数或者指令的地址,由 段(segment)+ 偏移(offset) 组成。
段标识符(segment identifier),即 段选择符(segment selector),是一个16bit字段(可以理解为段的索引信息)
- 段选择符由三部分构成:
- index(15bit):指明对应段描述符在GDT/LDT中的位置。
- TI(1bit):指示该段在GDT还是LDT中。
- RPL(2bit):表示访问该段所需要的CPU最低等级。
- 段寄存器存放段选择符: cs(代码段,同时标识CPU当前特权级)、ss(栈段)、ds(数据段)、es、fs和gs。
段的具体信息由 8字节 段描述符(segment descriptor)表示,所有段描述符存放在全局描述符表(GDT)或局部描述符表(LDT)里。
- GDT和LDT在内存里的地址和大小保存在
gdtr和ldtr控制寄存器里。 - 从段选择符查询段描述符的步骤:
- 根据TI判断出段在GDT还是LDT中;
- 根据index计算段描述符地址:index * 8 + gdtr的值;
- 由于段寄存器只保存16bit段选择符,为了能够快速从段选择符转换到段描述符,80x86提供一个非编程寄存器保存段描述符。当段寄存器载入一个新的段描述符时,查询对应的段描述符,然后装入到非编程寄存器中;之后该段描述符的转换就无需查询GDT/LDT,直接读非编程寄存器即可,可以省略上面的两个查询步骤。
偏移,是一个32bit字段。
- 从逻辑地址计算线性地址:
- 从段选择符可以查询到段描述符,段描述符的Base字段保存着该段首地址的线性地址
- 偏移量 + Base值 = 线性地址
线性地址
线性地址(linear address):一个32bit无符号整数,可以表示4GB内存,值的范围从0x00000000到0xFFFFFFFF。
页(page):把线性地址分成固定长度的组,每组称为页。
- 页可以在页框里,也可以在disk上。
页框(page frame):把物理地址分成固定长度的组,每组称为页框。
- 每个页框包含一个页
页表(page table):把线性地址映射到物理地址的数据结构,称为页表。
- 为了减小页表的大小,一般会有多级页表。32位系统用两级页表,而64位系统可能会用三级或四级页表。
- 页表存放在内存里,每个进程对应一份页表,维护着线性地址到物理地址的转换,由于页可以保存在页框也能放到disk上,这是VM的基础。
- 多级页表会影响效率,而且内存的速度比CPU要慢很多,所以增加了一个cache,即TLB。
物理地址
物理地址(physical address):用于内存芯片内的寻址单元,和内存总线的电信号对应,一般也是由32bit无符号整数表示。
全局段描述符表
一个CPU对应一个GDT。
GDT 的第一项是 null,这是为了保证一个空的段选择符将触发一个处理器异常。考虑一下:
一个空的段选择符必然index为0,那么在查询段描述符的时候,index * 8 + gdtr的值 = GDT的第一项,然后得到一个null,将触发处理器异常。
Linux下的内存寻址
Linux下使用分段很有限(因为RISC体系结构对分段支持有限),更多的使用分页来划分物理空间;所有进程使用同一组段寄存器值,意味着它们能够共享同一组线性地址。
Linux2.6仅在80x86结构下才使用分段,一共有18个段描述符,都保存在GDT中。包括用户态代码段、用户态数据段、内核态代码段、内核态数据段、局部线程存储段(TLS)、BIOS服务相关的段,等等:
| 段 | Base | G | Limit | S | Type | DPL | D/B | P |
|---|---|---|---|---|---|---|---|---|
| 用户代码段 | 0x00000000 | 1 | 0xFFFFF | 1 | 10 | 3 | 1 | 1 |
| 用户数据段 | 0x00000000 | 1 | 0xFFFFF | 1 | 2 | 3 | 1 | 1 |
| 内核代码段 | 0x00000000 | 1 | 0xFFFFF | 1 | 10 | 0 | 1 | 1 |
| 内核数据段 | 0x00000000 | 1 | 0xFFFFF | 1 | 2 | 0 | 1 | 1 |
可以看出四个段的线性地址都是从0开始,寻址限制是2^32-1,这意味着用户态或内核态下的所有进程将使用同样的 逻辑地址 = 线性地址。
不过注意到用户态和内核态的DPL是不同的,所以当特权等级发生变化时,需要刷新cs、ds和ss寄存器。
Linux进程
进程 = 线程组
在Linux2.6里的LWP即线程,所有的执行单位都是线程,进程应该理解为一个线程的组织,而非具体的执行单位了。
比如getpid()、kill()、_exit()这样的系统调用,都是针对一组具有相同pid的线程起作用,而非虚无缥缈的进程了。
书里经常有这样描述:线程组里的某一进程 (所以这里进程这个名字实际指的是轻量级进程,LWP,即线程)
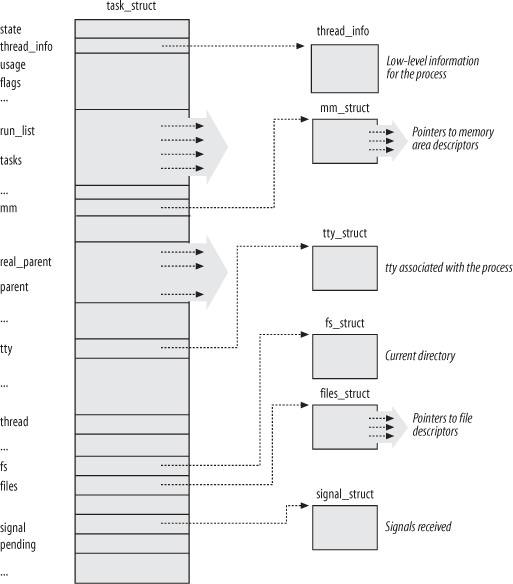
task_struct 进程描述符,定义在 include/linux/sched.h
state进程状态thread_info进程基本信息,指向一个线程描述符struct thread_infothread_info->task指向task_structthread_info和进程内核对栈并列放在两个连续的页框里,好处是检查栈就能获得当前进程描述符
tasks一个list_head头指针,用于进程链表parent标识父进程pid进程标识符- 循环自增整数,默认上限 32767 (
/proc/sys/kernel/pid_max) - 这个pid和我们默认理解的PID可能有些差异,因为pid是LWP标识,所以其实每个线程是有不同的pid的。
- 循环自增整数,默认上限 32767 (
tgid主线程的线程组标识符- POSIX 1003.1c规定同一线程组的所有线程必须有同样的PID
- 主线程的tgid == pid,当调用
getpid()时候,其实返回的是 tgid 的值,而非 pid
fs指向所打开的文件描述符signal指向所接受的信号描述符,同一线程组的所有线程共享同一组信号描述符。
为了快速的维护进程,相关的数据结构非常复杂,使用了非常多的链表和散列表。
进程 vs 线程
进程是资源管理单位,线程是内核调度单位。
- 创建进程(
fork())的开销远大于线程。子进程除了锁等特殊数据结构外,就是父进程的一个镜像;虽然是cow共享页框,但页表是必须复制的,当进程占用内存很大的时候fork,复制页表的开销会很大。线程只会有线程ID、栈、寄存器状态、信号掩码以及TLS等比较小的开销。但考虑资源管理方便的情况下,应该选择多进程,比如CPU affinity动态调整、调度优先级等等。 - 进程切换(
schedule()和switch_to())的开销稍大于线程。每个进程有一个TLB,而线程共享进程的TLB。在进程切换时TLB会flush掉,当然貌似也有lazy mode可以不完全flush;线程切换时TLB不受影响。尤其在不支持TLB id的体系上,切换MMU开销很大。 - 多进程往往比多线程更健壮。这也是很多服务器程序选择多进程模型的原因,一个进程core掉不至于影响整个服务。
进程调度
进程调度是对执行状态(TASK_RUNNING)的进程进行调度,即他们要抢占CPU,如果进程不可执行(正在睡眠或其他),那么它跟进程调度没多大关系。所以,系统负载越高,进程调度就越重要。
进程调度依赖分时(time sharing)技术,多个“同时”执行的进程以“时间多路复用”方式运行。分时依赖于定时中断,对进程是透明的。进程的优先级是动态的,由调度程序周期性的调整。在Linux2.6内核中,所有执行状态的进程按照优先级顺序被挂在一颗红黑树中,每次调度,schedule()函数找出优先级最高的进程,并随后将CPU分配给这个进程,时间复杂度为O(logN)。
Linux进程的调度类型有如下类型,普通进程和实时进程的调度算法并不相同:
SCHED_FIFO先进先出的实时进程SCHED_RR时间片轮转的实时进程SCHED_NORMAL普通的分时进程
普通进程的优先级算法
每个普通进程都有自己的静态优先级,从最高优先级100到最低优先级139。新进程总是继承父进程的静态优先级,调度程序使用静态优先级来评估该进程与其他进程之间调度的程度。
静态优先级决定了进程的基本时间片,公式如下:
若 静态优先级 < 120,则 基本时间片(ms) = (140 - 静态优先级) * 20
若 静态优先级 >= 120,则 基本时间片(ms) = (140 - 静态优先级) * 5
除了静态优先级还有动态优先级,也是从最高优先级100到最低优先级139。它与静态优先级的关系由如下经验公式表示:
动态优先级 = max(100, min(静态优先级 - bonus +5, 139))
bonus是0~10的值,与进程的平均睡眠时间有关。recalc_task_prio()函数负责更新程序的动态优先级。
内存管理
内核的内存管理
页框管理
Linux使用4KB页框(page frame)大小作为标准的内存分配单元。
页描述符,数据结构 page,用于记录页框的状态信息。
Linux2.6支持非一致性内存访问(NUMA)模型,在这种模型中,给定CPU对不同内存单元的访问时间可能不同。
分区页框分配器(zoned page frame allocator)的内核子系统,用于分配一组连续的页框。
函数 __get_free_pages()或alloc_pages()。
外碎片(external fragmentation):页框之间的碎片
伙伴系统(buddy system),解决分配大块连续内存问题,避免外碎片。
把所有的空闲页框分组为11个链表,每个链表分别包含1、2、4、8、16、32、64、128、256、512、1024个连续的页框。对1024个页框的最大请求对应着4MB大小的连续RAM块。每个块的第一个页框的物理地址是该块大小的整数倍。它的分配算法比较简单:
buddy_alloc(请求页框大小为2^n)
BEGIN
IF 相应的链表有空闲块
RETURN 该空闲块
ELSE
FOR 遍历11个链表中大于n的链表
IF 该链表有空闲块
切分出2^n大小的空闲块,剩余空闲块依次分隔插入到次小的链表中
RETURN 切分出的空闲块
END IF
END FOR
END IF
RETURN 错误
END
分配算法反过来就是回收算法,回收的时候内核总是试图把大小为b的一对空闲块合并为一个大小为2b的单独块,这也是伙伴系统得名的由来。
连续内存区管理
内碎片(internal fragmentation):页框内的碎片
slab分配器(slab allocator),解决小块内存分配的问题。比如,只在页框内分配几十、几百个字节,不至于页框被浪费严重
slab分配器把对象分组放入高速缓存。包含高速缓存的主内存区被划分成多个slab,每个slab由一个或多个连续的页框组成。有多种slab,比如,当一个文件打开时,相应“打开文件”对象所需的内存区从叫做flip(文件指针)的slab中分配。
slab分配器所管理的对象可以在内存中对齐,对齐因子是2的倍数,最大4096,即页框大小。
函数 kmem_cache_alloc()或kmalloc()。
非连续内存区管理
把内存映射到一组连续页框是最好选择,因为这样可以充分利用高速缓存。但如果对内存区请求不是很频繁,也可以通过连续的线性地址来访问非连续的页框。优点是避免外碎片,缺点是必须打乱内核页表。
函数 vmalloc() 或 vmalloc_32()。
Linux2.6还提供了一个vmap()函数,它将映射非连续内存区中已经分配的页框,该函数与vmalloc()相似,区别在于它不分配页框。
进程地址空间
用户态进程的内存管理
每个进程都有一个特殊的线性区,用于进程的动态内存请求,即堆(heap)。内存描述符的start_brk和brk字段分别限定了该区的开始和结束。进程可以使用如下API来请求和释放动态内存:
malloc(size)calloc(n, size)realloc(ptr, size)free(addr)brk(addr)直接修改堆的大小。参数指定current->mm->brk的新值,返回线性区新的结束地址。sbrk(incr)类似brk(),不过参数是指定增加还是减少以字节为单位的堆大小。
其中,brk()是唯一以系统调用方式实现的函数,其他所以函数都是使用brk()和mmap()系统调用实现的库函数。
中断
中断(interrupt)通常被定义为一个事件,该事件会改变CPU执行指令的顺序。
- 同步中断,被称作 异常 (exception)
- 由CPU控制单元产生。之所以称为同步,因为只在一条指令中止后CPU才会发出中断。
- 示例:由程序错误或内核异常产生,比如,信号、缺页异常、int或sysenter指令
- 异步中断,被称作 中断 (interrupt):
- 由其他硬件依照CPU时钟信号随机产生。
- 示例:由间隔定时期和I/O设备产生,比如,用户一次按键、IRQ(Interrupt ReQuest)
同步
抢占式内核的特点是,一个在内核态运行的进程,可能在执行内核态函数期间被另一个进程取代。
- Linux2.6中可以配置是否内核抢占。
- 内核抢占的好处是可以减少用户态进程的分派延迟(dispatch latency)
同步原语
- per-cpu variable
- 原子操作,比自旋锁和中断禁止都要快
- 80x86的原子指令示例:
- 原子操作一次对齐内存访问的汇编指令
- 操作码前缀 lock(0xf0)
atomic_t原子访问计数器
- 80x86的原子指令示例:
- 内存屏障
- 优化屏障(optimization barrier)
- Linux里的优化屏障是
barrier()宏,展开为asm volatile("":::"memory")
- Linux里的优化屏障是
- 内存屏障(memory barrier),在80x86中可用作内存屏障的汇编指令,比如:
- 对I/O端口操作的指令
- 有lock前缀的指令,比如读内存屏障
rmb()实现为asm volatile("lock;addl $0,0(%%esp)":::"memory") - Pentium4新引入的指令,比如读内存屏障
rmb()也可以实现为asm volatile("lfence")
- 优化屏障(optimization barrier)
- 自旋锁(spin lock),
spinlock_t结构- 一个内核控制路径独占临界区,其他路径忙等,不过一般内存资源只锁1ms左右
- 虽然锁住的进程不会被抢占,但是忙等的进程可能会被抢占
- 读写自旋锁,
rwlock_t结构- 读锁:多个读者读临界区,所有写者忙等
- 写锁:一个写者写临界区,所有读者、写者均忙等
- 顺序锁(seqlock),
seqlock_t结构- 写者永远不会忙等,除非临界区已经被另一写者锁住
- 缺点是读者不得不反复读取相同的数据,直到获得有效副本(判断
seqlock_t中的顺序计数器)
- 信号量(semaphore),
semaphore结构- 一个内核控制路径独占临界区,其他路径睡眠,相应的进程被挂起。
- 只有可以睡眠的函数才能获取内核信号量,中断处理程序和可延迟函数不能。
- 挂起进程
TASK_RUNNING->TASK_UNINTERRUPTIBLE,加入信号量等待队列
- 一个内核控制路径独占临界区,其他路径睡眠,相应的进程被挂起。
- 禁止本地中断
- 禁止本地软中断
- RCU(read-copy-update),类似
std::swap()思想,在Linux2.6中新增,用于网络层和VFS- 允许多个读者和写者并发执行,且无需锁
- 只保护动态分配且通过指针引用的数据结构
- 在RCU保护的临界区,任何读者、写者都不能睡眠
写控制路径进入临界区后必须禁用内核抢占? 可延迟函数?
内存屏障
内存屏障(Memory Barrier)的实质是对内存的操作施加顺序上的约束。
Memory barrier, also known as membar or memory fence, is a class of instructions which cause a central processing unit (CPU) to enforce an ordering constraint on memory operations issued before and after the barrier instruction.
至于“SMP情况下CACHE的一致性”只是内存屏障在执行lock、sfence、lfence等指令时的副作用。
Linux提供了一些内存屏障原语(它们只在SMP内核上生效):
smp_mb():一个既用于限制读操作也用于限制写操作的内存屏障。该屏障前的读写操作保证会在屏障后的任何读写操作之前完成。smp_rmb():内存读屏障。只用于限制内存读取操作。smp_wmb():内存写屏障。只用于限制内存写入操作。smp_read_barrier_depends():对其后续操作中所有依赖于其前导操作的部分,强制其顺序不变。这个原语在Alpha以外的所有平台上都是一个空操作。
线程mutex和信号量
pthread_mutex和semaphore均可以用作线程同步,同时后者还可以用作进程同步。
pthread_mutex和semaphore都由系统调用futex(2)实现。
信号
信号就是发送给线程或线程组的一个1~64的整数。
Linux下信号的最大值由宏 _NSIG 设置,同样信号掩码 sigset_t 的长度是两个unsigned long,即64位。
- 1~31是常规信号:信号并不排队,如果同一信号连续发送多次,那么只有一个能够发送到接受进程;但是可以挂起不同的信号(思考一下掩码)
- 32~64是实时信号:信号会排队
不应该依赖信号来传递更多的信息,信号的主要有两个目的:
- 通知进程已经发生了一个特定事件
- 强迫进程执行一个信号处理程序
信号的阻塞(屏蔽)
- 当屏蔽某一种信号时,在取消屏蔽前,进程将不接受该信号
- 当进程执行某一信号处理函数时,默认自动屏蔽该信号,直到信号处理函数执行结束。可知两点:
- 如果此时出现该信号,不会中断该信号处理函数,所以,信号处理函数不必是可重入的?
- 参考APUE 10.6节,提到信号处理函数应该是可重入函数,因为有可能在信号处理函数内中断外部的执行语句。比如在执行到malloc时,刚好中断函数内调用malloc,有可能破坏内存分配链表;再比如中断函数内修改了某个静态变量的值,也可能导致非预期效果。
- 结论:UTLK此处关于信号处理函数不必可重入的说法欠妥,只能说默认自动屏蔽相同信号,只能保证同一信号不冲突,而无法保证不同的且未屏蔽信号的冲突,以及信号处理函数和主函数的冲突。
- 例如:如果在信号处理函数里定义一个static变量,则该信号处理函数不是可重入函数,但此时由于自动屏蔽自身信号,所以是无碍的;但如果在信号处理函数里引用并修改外部的static变量,此时是可能导致不可预料的错误的。
- 如果设置
sigaction结构的sa_flags = SA_NODEFER,则可取消默认屏蔽同一信号。
- 如果此时出现该信号,不会中断该信号处理函数,所以,信号处理函数不必是可重入的?
SIGKILL和SIGSTOP不可以被显示的忽略、捕获和阻塞SIGKILL总是致命的SIGSTOP总是停止整个线程组
信号的传递
内核区分信号传递的两个不同阶段:
- 信号产生
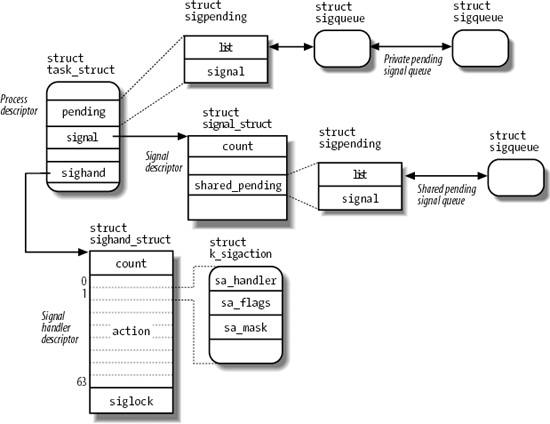
- 挂起信号(pending signal):已经产生但没有传递的信号会挂在当前
- 信号可以被挂起的时间不可预期
- 每个线程
task_struct都引用如下几个信号相关的数据结构:signal->shared_pending共享挂起信号队列(sigqueue),发给线程组的信号pending私有挂起信号队列(sigqueue),发给线程的信号sighand信号处理程序描述符(sighand_struct),所有线程共享clone( ... CLONE_SIGHAND ... )sighand_struct包含一个64长的数组,数组元素为k_sigaction(用户态即sigaction)
- 如果挂起信号数量太多,或超出资源限制,此时信号会丢失(
send_signal) - 宏
next_thread用于遍历线程组,执行信号处理函数
- 挂起信号(pending signal):已经产生但没有传递的信号会挂在当前
- 信号传递
- 信号由当前运行的进程,即
current进程传递 - 如果此时目标进程不在CPU上运行,内核会延迟传递信号
- 信号的传递次序是先从私有挂起信号队列,再到共享挂起信号队列(
dequeue_signal)
- 信号由当前运行的进程,即
POSIX 1003.1规定:
- 信号处理程序必须由整个线程组共享,但每个线程需要由自己的阻塞信号掩码和挂起信号掩码。
kill()和sigqueue()必须作用于整个线程组,所有由内核产生的信号也必须如此- Linux单独实现了
tkill(2)和tgkill(2),可以发送信号到单独线程(其实pthread_kill就是调用其实现的)
- Linux单独实现了
- 发送给线程组的信号仅会传递给一个线程(该线程是由内核随机选出来的)
- 如果向线程组发送一个致命信号(
SIGKILL),那么内核将杀死所有线程,并非仅接收该信号的线程
文件系统
文件锁,可以是共享读锁或独占写锁,一般有两种文件锁:
- 传统BSD变体
flock(),FL_FLOCK锁- 只能对整个文件加锁,且只产生劝告锁(advisory lock)
- 总是关联到一个文件对象。
- POSIX标准
fcntl(),FL_POSIX锁- 可以对文件区域加锁,根据
MS_MANDLOCK可以产生劝告锁或者强制锁(mandatory lock) - 总是关联到一个进程和一个inode。
FL_POSIX锁绝对不会被子进程通过fork()继承
- 可以对文件区域加锁,根据